
这门 MIT 课不教模型,教你怎么"想" AI
MIT 媒体实验室有个延续多年的传统,叫 “how to … almost anything”。最早是 how to make almost anything(怎么造几乎任何东西),后来有了 how to...


MIT 媒体实验室有个延续多年的传统,叫 “how to … almost anything”。最早是 how to make almost anything(怎么造几乎任何东西),后来有了 how to...

我以前一直觉得”做研究”是个挺玄的事:你得有灵感,得有品位,得在某天洗澡的时候突然冒出一个别人没想到的想法。后来在工程里摸爬几年,慢慢意识到大部分研究并不长这样。它更像一台机器,你按一个流程一圈一圈地转,转得快、转得...

ECS / OSS / CDN / 云数据库一站采购,常用云资源集中选配;新用户与续费均有专场优惠,适合个人开发者与小团队长期使用。

机器学习课的常见开场是讲算法:第一周线性回归,第二周决策树,第三周神经网络。Paul Liang 这一讲反着来。他先讲数据,而且讲了整整一节课,模型一个字没提。他给的理由很简单:你手里那摊数据长什么样,基本上已经决定了模型该长什么样,反过来...

第 4 讲是这门课第一次把人按到键盘前面。前三讲讲原则、讲研究、讲数据本身的结构,从这一讲开始,Paul Liang 把麦克风让给两位 TA:David 和 Chanaka,带大家在 Colab 里把一个分类模型从头跑通。 听上去像一节教 ...
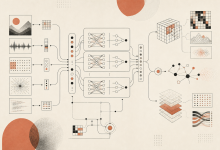
机器学习入门课的常见教法是:一周讲一个模型,线性回归、SVM、CNN、RNN、Transformer、GNN,一周一个,讲到学期末。学生记住了一堆名字,但下次拿到一个新数据集,还是不知道该选哪个,更不用说自己设计一个。 Paul Liang...

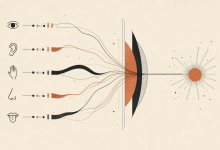
1976 年,一个叫 David McGurk 的心理学家做过一个实验。他给受试者放两段视频,画面里两个人在说话,音轨完全一样,但其中一个人的嘴型是发”ba”,另一个是发”fa”。受试者听到的...
机器人圈有句老话:传感器加一个,问题加十个。同事最初听到这话总觉得是抱怨,做久了才明白,它说的是一个具体的工程现象:你给机器人加一颗 IMU、一颗超声、一颗深度相机,它的感知能力并没有按”加法”涨,而是按”...

做机器人的人都熟悉一种处境:你想训一个新传感器上的模型,真实数据只有几千条,但同一个场景下,摄像头数据有几百万条、激光雷达数据有几千万条。你眼睁睁看着隔壁模态躺着金山,自己手里却只有沙子。 这不是你一个人的问题。医疗数据、生理传感器、嗅觉信...

监督学习像一次考试,你答一道题,老师立刻给分。强化学习不是。强化学习是你下一整盘棋,走了几十步,最后才知道这盘赢没赢,而且没人告诉你哪一步是关键的。这个差别看起来只是”反馈给得晚一点”,但它把整套训练范式都拧到了另一...

一门课的最后一讲,最能看出讲者真正在想什么。前面 11 讲是在搭骨架,数据、架构、对齐、融合、跨模态迁移、基础模型、强化学习,一块一块拼上去。到最后一讲,Paul Liang 不再讲新算法,而是退一步问:这些东西攒齐了,下一步应该长成什么样...

Paul 这一讲一开场就先打了个预防针:今天讲的是高度浓缩版的内容,MIT 隔壁的 ALP 那门课才是正经讲大模型,这里只是个高空俯瞰。听到一半我反而觉得,这种”俯瞰”才是真正值钱的。他把一个被无数公众号、技术博客、...

过去三年,做”语言+图像”的人几乎都在重复一个动作:拿一个已经训得很大的语言模型,死死冻住它,然后在它前面接一个很小的转接头,把图像、视频、传感器数据翻译成它认识的”词”。听起来像凑合,但这条...

 Toy
Toy





 Codex CLI 深度
Codex CLI 深度 AI 模型横评
AI 模型横评 AI Agent 框架
AI Agent 框架 Claude Code 订阅生存指南
Claude Code 订阅生存指南