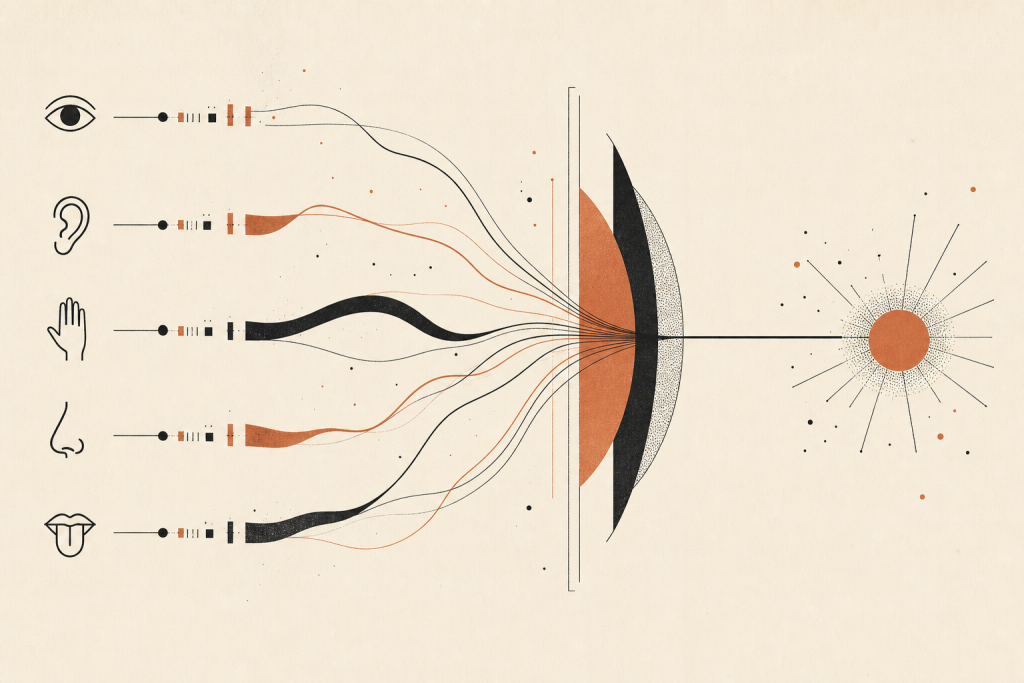
机器人圈有句老话:传感器加一个,问题加十个。同事最初听到这话总觉得是抱怨,做久了才明白,它说的是一个具体的工程现象:你给机器人加一颗 IMU、一颗超声、一颗深度相机,它的感知能力并没有按”加法”涨,而是按”乘法”出新的失败模式。原本视觉抓不到玻璃门,你期望激光雷达补上,结果激光雷达把玻璃直接穿透,两个模态合在一起反而比单一模态更糊涂。
这是 MIT《How to AI (Almost) Anything》的第 7 讲(原视频),主题是 多模态融合。这一讲我看完之后,最大的收获是:Paul Liang 用一节课把”融合”这件事的工程谱系完整拉开了,从最简单的相加,到外积、张量、低秩近似、门控、再到 transformer 早期融合,每一步增加的都不是参数,而是它能捕捉的”模态之间互相加乘”的能力。如果你只记一件事,记这句:融合的本质是让模态之间乘起来,不是拼起来。

这一讲的总判断:加法太弱,乘法才是融合
Paul 一上来就给”融合”下了一个干净的定义:给你两个模态,学一个联合表征(joint representation),让它能描述这两个模态怎么互相作用、信息来自哪边、又是怎么合并的。
这话听起来抽象,翻译过来是:你不能只把图像特征和文本特征拼在一起喂给一个 MLP,就管它叫”多模态模型”。那不是融合,那是并列。融合要求你显式地建模”模态之间的互相作用”,而互相作用最简单的数学形式,就是乘法。
第六讲讲的多模态对齐(alignment)解决的是另一个问题:冗余(redundancy)。两个模态里有共同的信息,对齐的方法把它抽出来,典型做法是对比学习。但模态之间不只有冗余,还有两种东西对齐方法是抓不到的:
- 独有信息(uniqueness):一个模态里有,另一个里没有。比如你说话内容是正面的,脸却是中性的。
- 协同信息(synergy):任何一个模态里都没有,只有两个合起来才浮现。比如说话内容正面、表情却是愤怒,合起来才能看出这个人在反讽。
对比学习处理冗余很好,但它会主动丢掉独有和协同,这是 Paul 反复强调的一句话,因为对比学习的损失函数就是把”两个模态相似的部分”拉近、不相似的推远,独有的部分自然被推走了。所以这一讲讲的所有融合方法,骨子里都在回答同一个问题:怎么把对齐丢掉的那两类信息捡回来。
从加法走到乘法:一行回归方程讲清楚
Paul 用了一个最简单的例子打底,我觉得是这节课讲得最漂亮的地方,值得抄一遍。
他设了一个图书评论的预测问题。两个输入模态:
- xa = 这个人讲这本书的时候,微笑的时间比例(连续值,0 到 1)
- xb = 这个人是不是专业书评人(0 或 1)
预测目标 y = 这本书的评分。
最直觉的做法是写一个线性回归:y = w0 + w1·xa + w2·xb。这就是加法融合(additive fusion),两个模态各自贡献,谁也不依赖谁。画在图上,xb 取 0 和 1 是两条平行线,专业书评人整体打分偏低(w2 < 0),但他们微笑和评分的关系,跟普通人完全一样的斜率。
但生活里不是这样的。直觉告诉你:专业书评人微笑这件事,比普通人微笑更值钱。普通人看书随手笑笑很正常,书评人能笑出来,说明这本书是真不错;书评人板着脸,那这本书大概率烂透了。换句话说,xa 对 y 的影响,得条件在 xb 上。
数学上要表达这件事,你得多加一项:y = w0 + w1·xa + w2·xb + w3·xa·xb。最后这一项就是乘法交互(multiplicative interaction)。两个模态相乘,再乘上一个权重 w3。引入这一项之后,xb 取 0 和 1 不再是两条平行线,而是两条斜率不同的线,书评人那条更陡,意味着他们微笑的边际效应更大。
这个例子的妙处在于,它把”为什么要做融合”这件事讲透了:只要你认为模态 A 的影响要条件在模态 B 上,你就需要乘法项。加法项做不到这件事,加再多模态、用再深的网络,只要结构上是 f(a) + f(b),它就只能画平行线。
把乘法推广:从向量到矩阵到立方体
一维讲清楚之后,Paul 把乘法推到高维,这一段是工程上最实用的部分。
两个模态都是 4 维向量怎么办?最简单的写法是逐元素相乘(element-wise product):xa 的第 1 维乘 xb 的第 1 维,第 2 维乘第 2 维……得到一个 4 维的融合向量。便宜、高效,但不够表达:它只让”对应位置”的特征相乘,xa 的第 1 维和 xb 的第 3 维永远不会相遇。
更”贪婪”的做法是外积(outer product):xa 是 4×1,xb 是 1×4,相乘得到 4×4 的矩阵。这个矩阵里,xa 每一维都和 xb 每一维交叉一次,捕捉所有 pair-wise 的乘法交互。这个东西在多模态领域有个老名字叫双线性池化(bilinear pooling),现代 transformer 里的注意力矩阵跟它是远房亲戚,transformer 里 query 乘 key^T 得到的注意力图,本质就是一个 token 序列对另一个 token 序列的 pair-wise 乘法。
Paul 顺手补了一个小技巧:做外积之前,在每个向量末尾追加一个 1。这样得到的 5×5 矩阵里,既有 4×4 的双模态乘法块,又自动保留了 xa、xb 各自的单模态项和常数项。一行代码,把加法和乘法一锅烩了,这种工程审美值得偷过来。
三个模态呢?外积升到三维,变成一个 4×4×4 的立方体(tensor),立方体内部捕捉三模态联合乘法,三个面捕捉两两 pair-wise,三条边捕捉单模态。你可以推到任意维度,但问题来了,四个模态就是 4×4×4×4 = 256 个参数,五个模态指数爆炸。
这时候就轮到低秩近似(low-rank approximation)登场。Paul 给的直觉很白话:一个 10×10 的矩阵看起来有 100 个参数,但很多维度之间是相关的,你可以把它分解成几个外积之和,比如两个外积加起来只有 10+10+10+10 = 40 个参数,精度可能掉得不多,但参数砍掉一大半。今天大模型微调里满地跑的 LoRA(Low-Rank Adaptation),用的就是同一个数学,只不过场景是把 768×768 的注意力权重压成几对小向量。多模态融合最早玩的这套数学,十年后被 LLM 微调捡去用,是这一讲里我觉得特别值得停下来嚼一遍的脉络。
静态权重不够,得让模型”看人下菜”
到目前为止讲的所有方法,权重都是固定的:训完之后 w1、w2、w3 就钉死了,所有数据点共用一套。但现实里,一个模态有没有用,得看当下这条数据。同一个机器人,在亮堂的商场里视觉特别可靠,进了昏暗的车库视觉就基本作废,这时候模型应该自动把权重切到激光雷达上去。
Paul 把这类方法统称为门控融合(gated fusion)或者动态融合(dynamic fusion)。权重 w1、w2 不再是常数,而是当下输入的一个函数 g(xa, xb)。你可能听过另一个名字,这其实就是注意力机制在多模态场景下的另一种写法。门控可以是软门(soft attention,0 到 1 之间的连续值)也可以是硬门(hard attention,只取 0 或 1)。硬门更可解释(你直接看哪些特征被选中、哪些被砍掉),但因为是离散的,反向传播不友好,训练起来比软门难。
还有一种结构 Paul 单独点出来,叫主从模态融合(modality shift)。出发点是个常识:人沟通时大部分信息来自语言,语调和表情是细微修正。所以模型把语言定为主模态(primary),用一个 transformer 拿到它的句向量(就是开篇说的嵌入,embedding,向量),然后让视觉和音频学一个”小幅修正”加到这个句向量上。几何上理解,语言嵌入是空间里的中心点,非语言信号轻推它一下偏向某个方向。
这个设计放到机器人上完全成立:主模态是激光雷达建的占据栅格地图,视觉和力觉提供局部修正,比如视觉发现前面有反光玻璃门,就在栅格的对应位置”推一下”,把那块从可通行改成不可通行。比对每帧都做对称融合,这种主从结构计算量小一个数量级。
早期融合 vs. 晚期融合:把活留给模型还是留给特征
讲完一连串方法,Paul 把谱系两端拎出来对照:
- 晚期融合(late fusion):每个模态各自走一个预训练编码器抽出干净的特征,再做一个简单融合,比如直接拼接、加权平均,甚至只在最后投票。好处是特征已经”对齐到语义空间”了,视觉模型抽出来的”狗”和语言模型抽出来的”狗”语义上已经接近,融合不用做重活。
- 早期融合(early fusion):把原始数据尽早拼起来,丢给一个大模型自己摸索怎么用。好处是不损失任何细节,坏处是模型得自己学怎么处理量纲、维度、连续/离散全不一样的原始数据。
今天的大模型基本都倒向早期融合,代价是模型得足够大。Paul 提了一个老掉牙但仍然有效的提醒:很多看起来很复杂的融合模型,做出来的事情其实和简单加法没区别。他引用了一篇文章的实验:把一个复杂模型在多模态任务上跑出 91% 的准确率,然后把它投影到最近的纯加法模型上,准确率只掉到 91.1%。再换个数据集,81.5% 掉到 81.3%。
读到这里我停下来想了很久。所谓”投影到加法模型”,数学上是把 f(xa, xb) 拿过去,对 xb 求期望得到一个只依赖 xa 的函数,对 xa 求期望得到一个只依赖 xb 的函数,两者相加。如果这两个加起来就能逼近原模型,说明你那套花里胡哨的双线性池化、tensor、transformer 之间的协同信息,根本没学到,模型只是把两个模态各自学了一遍然后相加。这是一个非常残酷的诊断工具:你以为你做了融合,实际你做的只是更贵的加法。
Paul 顺手介绍了一个对策,叫残差式分阶段训练:先只用单模态特征训出一个加法模型,看剩下多少误差;再用两两交互去拟合这部分残差;最后用三模态交互拟合剩下的残差。每个阶段只啃前一阶段啃不下来的部分,逻辑上保证每加一阶都至少不会更差。这套思路和梯度提升树异曲同工,工程上也容易调试:你能清楚地看到加完两两交互之后误差下降了多少,值不值得再加三模态。
融合训不动,通常是模态学习速度不一样
这一讲最后,Paul 花了不少时间讲多模态融合训不动的常见原因,这部分对工程师比理论部分更有用。
第一个坑是单模态偏置(unimodal bias)。经典的视觉问答(VQA)数据集里,问”香蕉是什么颜色”,训练集里几乎全是黄香蕉,模型学到的策略很简单:看见问题里有”banana”,直接回答”yellow”,图像那一路根本不看。给它一张青色的香蕉,它照样答黄色。这不是融合失败,这是模型发现单模态就够拿分,直接放弃了另一个模态。VQA 2.0 的解决方案很笨但有效:每个问题强制配两张能给出不同答案的图,逼模型必须看图。
第二个坑是模态学习速度不匹配。语言路径已经过拟合了,视觉路径还没收敛,这种情况下,梯度大部分都流向语言,视觉这边永远长不出有用的特征。一个解法是同时训一个多模态模型加两个单模态模型,拿单模态的学习曲线当基准,实时调节多模态里每条路径的学习率。Paul 自己也承认:”代价是你得训三个模型,不太划算。”这种”诚实承认方案有副作用”的态度,是这门课让我喜欢的另一个原因。
我会怎么用 / 放到机器人上看
我做的是机器人云服务,清洁机器人和服务机器人上的多模态融合是我们每天都在改的东西。这一讲对我有几个非常具体的落点。
第一个落点是”加法还是乘法”的诊断工具。我们机器人上跑的低层感知融合,长期是一套加权卡尔曼滤波,骨子里就是加法融合:激光雷达置信度 + 视觉置信度 + IMU 置信度,加权出一个状态估计。这套东西在常规场景下很稳,但在反光玻璃门、夜间无光、深色地毯这几个老大难场景上反复栽。Paul 的那个”投影到加法模型只掉 0.1%”的实验给了我一个直接可用的反向诊断:如果一个场景下,我们现在的”加权融合”和”理想融合”差距很小,说明这个场景里模态之间本来就没什么协同信息,优化空间不大;但如果差距很大,就该上乘法交互的结构,比如把视觉特征和激光雷达特征做一次双线性池化,看效果。
第二个落点是主从融合的工程现实意义。我们的栈里激光雷达是绝对主模态,建图、定位、避障的骨干全是它。视觉、超声、碰撞传感器是次模态。过去我们做融合的方式很笨,要么所有模态平等参与,要么手写一堆 if/else 切换主次。Paul 讲的 modality shift 给了一个干净的写法:在主模态的特征空间里,让次模态学一个小幅平移向量,只在主模态置信度低的时候让平移生效。这个改造可以做在云端模型上,不影响机端的实时性。
第三个落点是单模态偏置的诊断。我们的清洁机器人在某些场景下会重复同一种动作,我之前一直怀疑是某个模态被”短路”了:模型发现只看里程计就能拿到训练集上的大部分奖励,直接懒得看视觉。Paul 讲的 VQA 香蕉例子和我们的现象几乎是一回事。诊断方法也很直接:遮掉视觉输入跑一遍,看输出变化多大。变化小,就是被短路了;变化大,说明视觉真的在被使用。下周就可以让团队跑一遍。
第四个落点是关于 transformer 早期融合的现实选择。学术界这两年的多模态模型已经全面倒向”把所有模态 token 化,塞进一个大 transformer”。我们工程上一直没敢这么做,主要是机端算力不够。但 Paul 提醒了一件容易忽略的事:早期融合不一定要在端上做,完全可以把机端各模态特征上传到云端,在云端做大 transformer 融合,再把决策结果发回去。延迟换准确率,是个工程权衡题,不是算力天花板问题。
收束
这一讲有不少数学,但骨架其实非常干净:两个模态之间,只有加法是不够的,你得让它们乘起来,而怎么乘、乘多少、什么时候让某一项静默,就是这套谱系上几十种方法的全部分歧。
第 6 讲讲对齐,捡的是冗余;第 7 讲讲融合,补的是独有和协同;第 8 讲会讲跨模态迁移,数据少的那个模态,怎么靠数据多的模态借光。三讲连起来,就是 Paul 这门课多模态模块的整张地图。
本系列
MIT《How to AI (Almost) Anything》共 12 讲,这是我的逐讲解读:
- 这门 MIT 课不教模型,教你怎么”想” AI
- 怎么做 AI 研究:读论文、找想法、快速验证
- 数据、结构与信息
- 实用 AI 工具
- 常见模型架构
- 多模态对齐
- 多模态融合不是把数据拼起来,是让模态之间”乘起来” (本篇)
- 跨模态迁移
- 大型基础模型
- 大型多模态模型
- 强化学习与交互
- 人机交互