
机器学习入门课的常见教法是:一周讲一个模型,线性回归、SVM、CNN、RNN、Transformer、GNN,一周一个,讲到学期末。学生记住了一堆名字,但下次拿到一个新数据集,还是不知道该选哪个,更不用说自己设计一个。
Paul Liang 这一节课反过来。他把所有这些架构塞进一个统一的框架里讲,讲完你会发现 CNN、Transformer、RNN、GNN 不是四种东西,是同一套乐高,怎么搭、搭进去多少关于数据的”先验”,决定了它的名字。

这是 MIT《How to AI (Almost) Anything》的第 5 讲(原视频),主题是 常见模型架构。
一句话总判断:模型设计就是把数据的对称性”焊”进结构里
整堂课最值钱的判断,Paul 没用一个口号去概括,我替他写:
设计一个深度学习模型,核心就是回答两件事:怎么从原始数据里抽出表征(representation),怎么把多个表征组合起来。剩下的所有花样,都在回答一个更狠的问题——你的数据有哪些变换是不该影响结果的(不变性),哪些变换是必须被模型感知到的(等变性)?把这两件事想清楚,用最少的参数把它们焊进架构里。
这话听起来抽象,但它解释了一个很现实的现象:为什么有些模型用一万条样本能学会,有些模型用一百万条都学不动?差别不在算法,在你有没有把数据本身的对称性提前告诉模型。
Paul 给了一个很硬的反例:同样是处理一组(无序的)图片找异常,如果你的模型不做参数共享、用拼接(concatenation)代替求和去聚合特征,那它需要的训练样本是正确设计的 120 倍(5 的阶乘)。五张图就 120 倍,十张图就是 360 万倍。这种差距不叫”略多一点”,叫直接训不动。
所以这门课的”原则”派教法,在架构这一节落到一个非常具体的工程动作上:动手前先列两份清单。这数据,哪些变换我不该敏感?哪些变换我必须敏感?
模型不是积木盒,是两种操作的反复嵌套
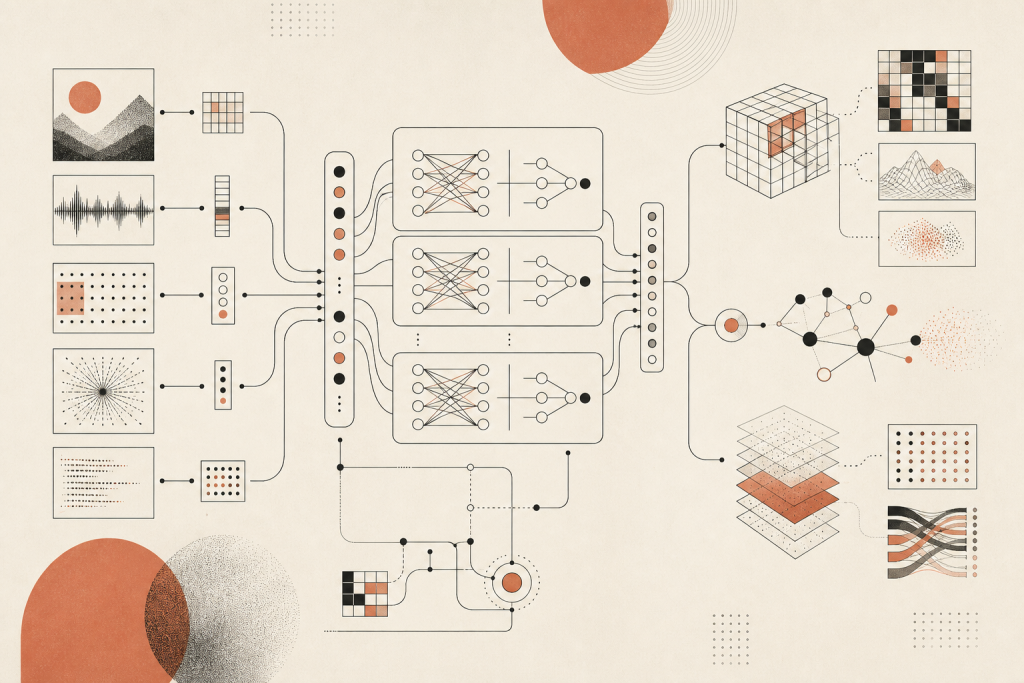
Paul 让大家先放下”这是 CNN、那是 Transformer”的标签,回到最底层看:任何一个现代深度模型,你拆到最里面,只有两类操作在反复出现。
第一类是学表征:把高维原始数据(像素、词、传感器读数)压成一个低维但语义更稠密的向量。常用积木是全连接层(矩阵乘法)、激活函数(ReLU 这类非线性,没它就只能学线性函数)、层归一化(把数值规范到合理区间)、卷积、自注意力。
第二类是聚合表征:把多个局部表征合成一个更高层的表征。常用积木是拼接、加和、逐元素取最大、交叉注意力。
剩下的就是把这两类积木以不同的顺序、不同的连接方式堆起来,前向算 loss,反向求梯度。Paul 说,你读任何一篇 transformer、CNN、扩散模型的论文,本质都是在告诉你”我把这些积木换了一种摆法”。
这个视角看下来,模型设计就只剩一个问题:该怎么摆?答案就是上一节的总判断:看数据的对称性。
点云、图像、文本,其实都是同一个问题的不同切片
Paul 把这个框架挨个套到四类经典数据上,我重新组织一下。
集合(set)和点云。集合的关键特性是无序。给你一堆图片找异常,我先给 A B C D E 你回答的异常图,和我打乱成 E C D B A 再问,你的答案应该一样。这叫置换不变性(permutation invariance)。要把它焊进模型,只需要两件事:每个元素用同一套参数去抽特征(参数共享),抽完用一个对顺序不敏感的函数去聚合(比如求和、取最大)。这就是 PointNet 这类点云模型的全部内核。
如果你违反任何一条会怎样?Paul 演示得很清楚:不共享参数,等于告诉模型”A B C D E”和”E A B C D”是完全两组不同的数据,模型为了学到它们其实代表同一个集合,需要把所有 120 种顺序都喂一遍。哪怕你做了参数共享,但聚合函数选了拼接而不是求和,顺序又会改变输出,模型一样需要 120 倍数据才能学会”顺序无所谓”。
序列数据。把”集合”换成”句子””时间序列””基因序列”,对称性反过来了:模型应该对时间轴的整体平移不敏感(把整句话往前往后挪一格,不该改变意思),但必须对词序敏感(fox jumps over dog 和 dog jumps over fox 不是一回事)。
这两个性质决定了序列模型的两条铁律:跨时间步参数共享,跨时间步信息累积。RNN 的循环、LSTM 的门控、TCN 的因果卷积、状态空间模型(SSM)、Transformer 的自注意力,Paul 强调,这些”换代”的模型在两条铁律上完全一致,只是聚合的方式从”串行累积”换成了”并行注意力”。所以”RNN 已经过时”是误读:它的继承者一路从 LSTM 走到 TCN 再到 SSM,在处理长时间序列时,SSM 至今仍是 Transformer 的强劲对手。
注意力机制是从机器翻译里长出来的。Paul 翻出了那篇里程碑的论文,展示了英译法的注意力热图:对角线最亮,意思是大部分情况下英语第 i 个词对应法语第 i 个词,但偶尔有几个亮点偏离对角线,那是英法语序不同的地方(形容词后置之类)。这张热图就是注意力的来历:动态地按相关度分配权重,而不是把上下文一锅端聚合。
注意力的公式也可以从这个视角去看,而不是死记 Q K V。三个词的输入是 3×d,WQ 把它投到查询空间,WK 投到键空间,二者外积得到 3×3 的两两相关分数;除以 √d 是为了控制方差(不然 d 一大,内积就爆炸),softmax 让每行归一成概率,再去和值向量(WV 投出来的)加权求和。整个过程是在算”每个词应该看其他词的哪些部分,看多少”。
空间数据。一张 200×200 的图,直接拍扁丢进全连接,第一层就是 40000×n 的矩阵,既贵又不抗平移。卷积的两个想法解决了这两件事:一是稀疏连接,每个输出位置只看附近 3×3 这么大一窗,这叫局部性;二是窗口内参数共享,同一组权重扫遍全图,这就是平移不变性。再加一个 max-pooling 取局部最大,让模型对小幅抖动更不敏感,同时被迫去看更宏观的结构。
经典的 CNN 可视化早就说明白了:第一层学边缘,第二层把边缘组成形状,再往上学到部件,最后才是整体识别。这是”层级组合”的具体表现,跟前面说的”反复嵌套表征学习和聚合”是同一回事。
视觉 Transformer(ViT)把图切成 K×K 的小块,把这些块当成一个”序列”去做自注意力。Paul 提醒一句话就够:ViT 的两条铁律和 CNN 一样。切块之后所有块共用同一套 transformer 参数(参数共享),注意力把信息跨块聚合(信息聚合)。形状不一样,内核完全一样。
中途有学生问:为什么图像就一定是平移不变的?红块在黑块上面和翻过来不一样啊。Paul 的回答很 Karpathy:对称性是由任务决定的,不是由数据决定的。分类任务里,把红黑块上下翻还是同一类,所以模型应该不变;分割任务里,你要输出每个像素的类别,翻一下输出图也得跟着翻,这叫等变(equivariant)。先想清楚你的任务里哪些变换是噪声、哪些是信号,再决定模型该不变还是等变。
图(graph)数据。Paul 把图放在最后讲,因为图是这些数据形态的”超集”。图神经网络的核心也是两件事:每个节点用同一套参数抽特征(参数共享),按照边的连接结构去聚合邻居的特征。
然后他做了一个我觉得整堂课最优雅的演示:
- 把图里的边全部抽掉,只剩孤立节点 → 你得到了集合(没有邻居可聚合,只剩参数共享)。
- 把图按上下左右四邻居网格化 → 你得到了图像(卷积就是在网格图上做局部聚合)。
- 把图拉成一条链,每个节点只连前后 → 你得到了序列(RNN 就是在链图上做单向聚合)。
CNN、RNN、Transformer、GNN 看起来是四种架构,其实是同一种东西在不同连接结构上的退化形态。
这套框架对工程决策的真正用处
Paul 在结尾把这一讲缝回了上一节”数据”,提了一个绕不开的工程判断坐标轴:从”领域定制”到”通用模型”是一个谱,你设计的每个模型都坐落在这条谱上的某个位置。
- 领域定制的一头:把数据的对称性、专家知识全部硬编码进结构,样本少也能学,但换个问题就废。
- 通用模型的一头:不假设结构,靠堆数据和算力去学,什么都能干,但代价是吃数据吃算力。
这门课的剩下两个模块(多模态、大模型)其实就是顺着这条谱走:多模态在中段,既要为每种模态保留一些定制结构,也要为模态间的交互留通用的接口;大模型走到了另一头,什么先验都不要,只靠规模。
这条谱本身就是工程决策的判断框架:手里数据多到能砸,选通用;数据稀缺、对称性又明显,把对称性焊进结构里能省几个数量级的样本。两端没有道德高下,只有适不适合手头的问题。
放到机器人现场看:这门课是为我们这种人写的
我做的是清洁/服务机器人的云服务,这一讲对我特别有共鸣。一台机器人本身就是一个 Paul 所说的”数据对称性混合体”:
- 激光雷达扫一帧,就是一团点云,跟 Paul 一开始举例的集合数据完全对得上。每个点是 (x, y, z, 强度),点和点之间没有”先来后到”,你旋转一下输出顺序结果也不该变,典型的置换不变。所以我们后端做障碍物聚类、语义分割,走的就是 PointNet/PointNet++ 那一脉的思路,共享 MLP + max-pool。这种写法不算”用了一个很 fancy 的网络”,数据的对称性本身就要求你这么写。
- IMU、轮子里程计、电机电流,是标准的时间序列。机器人卡了、轮子打滑了、刷子被毛发缠死了,这些信号都体现在某个时间窗内的电流波形上。我们要的模型,对”这个事件发生在 10 秒前还是 11 秒前”不敏感(时间平移不变),但对”先卡死再加速”和”先加速再卡死”必须区分(顺序等变)。所以我们做异常检测,用过 LSTM、TCN,最近在试 SSM,走的正是 Paul 说的”RNN 没死,在演化”那条线。
- 摄像头帧,就是平移不变的空间数据。识别玻璃门反光、识别地面湿滑、识别小孩突然冲出来,我们用 CNN 也用 ViT,选谁看的是那一类场景里小目标多不多、上下文需要看多远,这又落回 Paul 说的”先看你的不变性和等变性需要什么”。
- 传感器之间的关系,其实是一张图。哪个雷达和哪个相机是同轴标定的、谁的时间戳应该绑谁,这是一张连接关系图。多传感器融合在我们这边,某种意义上就是在这张图上做信息聚合。
Paul 最后用图把集合、序列、空间数据缝在一起的那一幕,对我来说更像一个工程总结:一台清洁机器人在地下停车场里转一圈,它产生的数据里同时含着集合(点云)、序列(IMU 时间轴)、空间(相机帧)、图(传感器拓扑)。我们做云端数据平台,要做的事情正是为这四种数据形态各自选合适的”积木摆法”,同时为它们之间的交互留接口,这恰好就是这门课接下来要讲的多模态对齐和融合。
还有一个特别接地气的细节我想留下来。Paul 提到,把摄像头挡住,机械臂能切回靠力觉完成任务。这件事在我们的清洁机器人上是反过来的:激光雷达看不到玻璃门(玻璃没反射),靠超声波或者碰撞传感器补;摄像头被水雾糊住了,靠雷达和 IMU 撑;一个传感器的”对称性假设”破了,另一个传感器接住。这种”传感器降级”的工程逻辑,跟 Paul 说的”为什么要冗余传感器”是同一个判断:多模态冗余的真正理由,在于不同模态对不同噪声的不变性结构不一样,谁失效了,另一个的等变性还在。
所以这门课对我的价值,不在于教我新模型,而在于把我们在现场摸出来的那堆 trick,放到了一个干净的语言里。下次招人,我大概会拿置换不变性这一段当面试题,比”你会写 PyTorch 吗”信息量大多了。
收束
这一讲最值得带走的就一件事:架构没有那么神秘,神秘的是你愿意花多少功夫去搞清楚你的数据里藏着什么对称性。搞清楚了,模型只是把它们焊起来;搞不清楚,你就只能靠堆数据和算力去逼近,而数据和算力对绝大多数团队来说不是无限的。
下一讲开始进入”多模态”模块,Paul 说重点会从单一模态的架构,转到模态和模态之间该怎么对齐。我会接着写。
本系列
MIT《How to AI (Almost) Anything》共 12 讲,这是我的逐讲解读:
- 这门 MIT 课不教模型,教你怎么”想” AI
- 怎么做 AI 研究:读论文、找想法、快速验证
- 数据、结构与信息
- 实用 AI 工具
- 常见模型架构 (本篇)
- 多模态对齐
- 多模态融合
- 跨模态迁移
- 大型基础模型
- 大型多模态模型
- 强化学习与交互
- 人机交互








