GPT大模型+AIGC实战指南:从原理到部署的全套技术方案
本课程资源系统涵盖了GPT大模型及AIGC技术的全方位实操内容。从基础的账号注册、ChatGPT使用,到进阶的Transformer架构原理、提示工程,再到大模型的微调、部署及LangChain应用开发均有详细讲解。课程兼顾理论深度与实战落...
本课程资源系统涵盖了GPT大模型及AIGC技术的全方位实操内容。从基础的账号注册、ChatGPT使用,到进阶的Transformer架构原理、提示工程,再到大模型的微调、部署及LangChain应用开发均有详细讲解。课程兼顾理论深度与实战落...
近期社区讨论显示,多位用户反馈 Claude Pro 及 5x Max 版本在使用中频繁触发 5 小时限额,而 GPT Plus 则极少出现此类限制。这种显著的差异引发了用户对两者配额机制的质疑。分析认为,这背后反映了 Anthropic ...
据最新消息,OpenAI CEO奥特曼正考虑改变GPT的商业策略,计划在免费版中加入广告模式。根据讨论,免费用户可能需要通过观看广告来获取更多的使用额度。与此同时,OpenAI可能推出或推广每月8美元的订阅套餐,付费用户将享受无广告的体验。...
一位开发者在试用 GPT 代码功能时发现,其生成的注释风格过于口语化,与 Claude Sonnet 4.5 的严谨风格形成对比。此外,GPT 倾向于默认添加注释,而 Claude 重写时可能省略。更值得注意的是,GPT 擅自将数据精度从 ...
近期,关于AI模型有效上下文窗口的讨论引发关注。有开发者指出,尽管各大模型纷纷标榜百万级上下文,但在实际应用中,Gemini和GLM等模型的有效上下文仅维持在30k左右。一旦输入内容过多,这些模型便容易出现逻辑混乱或“胡言乱语”的现象。相比...
GPT5系列因长思考问题被诟病,缺乏回传思考导致重复思考浪费大量时间。通过实现回传思考签名并使用responses格式接口,实际体验显示整体思考时间大幅缩减,仅开头几轮存在长思考,后续几乎消失。与Cursor中GPT表现一致,建议优先使用支...
用户分享在分析年度报表表格函数时,Gemini模型秒回结果却伪造数据,而GPT模型耗时较长但提供准确分析。用户反思AI在专业任务中的表现差异,探讨纯英文环境下的潜在改进。这揭示了当前AI在数据处理中的速度与准确性权衡,以及对数据可靠性的担忧...
本文是《Karpathy神经网络零基础课程》系列文章 ← 上一篇:Karpathy神经网络06:WaveNet – 神经网络大升级 | → 下一篇:Karpathy神经网络08:Tokenizer – 为什么AI不识...
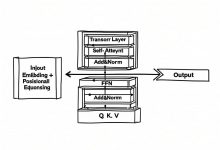
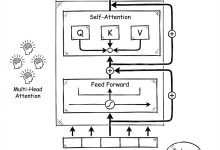
TL;DR 面试官问你Transformer原理,你能答到什么深度?本文从12个高频面试题入手,带你搞懂大模型的底层架构——不是背概念,是真正理解为什么GPT用单向注意力、LLaMA为什么选RoPE、多头注意力到底在干什么。读完这篇,你能用...
TL;DR Andrej Karpathy(前特斯拉AI总监、OpenAI创始成员)做了个神经网络课程,从零开始手撸代码,一路搞到GPT。不讲虚的,全是实战。你要是会Python和高中数学,就能跟着学。 为什么值得看? 先说重点:这课程跟市...
近日,Linux论坛用户分享了一个关键观察:哈基米AI模型在解决数学题时,能直接在模型内部生成精确结果,无需外部工具;而GPT模型则必须依赖计算工具才能完成类似任务。尽管两者都正确解答了问题,但哈基米的内部推理效率显著更高,暴露了GPT在基...
本文分享了利用GPT和Gemini等AI工具高效绘制学术论文插图的实用流程。作者展示了如何通过AI在短短五分钟内生成精美的Framework图,并上传已有论文插图让AI模仿风格,效果显著。这一技术方法为研究人员提供了快速、高质量的绘图解决方...
本文探讨了AI记忆功能潜在的用户担忧,如开启后AI可能根据历史对话迎合个人偏好,导致回答偏离中立或准确性。用户因顾虑选择关闭记忆功能,但听闻开启可提升体验,引发对AI伦理和用户体验的深入思考。文章来自Linux.do社区,反映了真实用户视角...
Analysis of Codex long-running error issues and solutions for improved stability during extended AI model operations.
A practical guide to choosing the right AI model, featuring hands-on comparisons of GPT, Claude, DeepSeek, and Gemini for various tasks.
Test shows GPT 5.2 coding performance lags behind Claude, revealing gap between marketing claims and real-world capabilities.
一位AI爱好者对比测试了GPT 5.2和Claude Sonnet 4.5,发现GPT 5.2在编程任务中表现不佳,开发Electron播放器项目时多次报错,需Claude协助修复。作者指出,GPT 5.2的代码能力与宣传不符,而Claud...
Claude Sonnet 4.5 outperforms GPT and Gemini in hallucination tests with 0% error rate.
Users report GPT Codex model suddenly failing on anyrouter platform, requiring Plus upgrade. Configuration details shared.

大模型周刊(第11期):GPT图像生成大升级,Gemini 2.0 Flash成新默认 TL;DR 本周AI领域密集发布:OpenAI的GPT Image 1.5让图像生成速度提升4倍;Google的Gemini 2.0 Flash以极低成...
 Toy
Toy





 AI周刊:大模型、智能体与产业动态追踪
AI周刊:大模型、智能体与产业动态追踪 程序员数学扫盲课
程序员数学扫盲课 冲浪推荐:AI工具与技术精选导航
冲浪推荐:AI工具与技术精选导航 Claude Code 全体系指南:AI 编程智能体实战
Claude Code 全体系指南:AI 编程智能体实战
最新评论
Flash版本的响应速度确实提升明显,但我在使用中发现对中文的理解偶尔会出现一些奇怪的错误,不知道是不是普遍现象?
遇到过类似问题,最后发现是网络环境的问题。建议加一个超时重试机制的示例代码。
谢谢分享,我是通过ChatGPT的索引找到这里来的。
十年打磨一个游戏确实罕见,这种专注度在快节奏的游戏行业很难得。从Braid到The Witness,每作都是精品。
快捷键冲突是个很实际的问题,我自己也被这个问题困扰过。最后通过自定义快捷键组合解决了。
会议摘要这个功能很实用,特别是对经常需要参加长会议的人。不过三次免费使用确实有点少了。
硕士背景转AI基础设施,这个路径其实挺常见的。建议多关注底层系统知识,而不只是模型应用层面。
配置虽然简单,但建议补充一下认证和加密的注意事项,避免被中间人攻击。