
while 循环谁都会写,差距全在你喂给 LLM 的那串文字
作者:toy 先把两个词分清楚:Context 和 Context Window 不是一回事 这两个词被混着用太久了,写代码的时候迟早会踩坑。 上下文(Context),指的是 Agent 在执行任务时,实际拥有的所有信息。系统提示词、对话...


作者:toy 先把两个词分清楚:Context 和 Context Window 不是一回事 这两个词被混着用太久了,写代码的时候迟早会踩坑。 上下文(Context),指的是 Agent 在执行任务时,实际拥有的所有信息。系统提示词、对话...

这篇文章讲的是一个很容易被低估、但几乎所有 Agent 产品都会撞上的问题:上下文管理。Sally-Ann Delucia 这场分享的价值很直接,她没有泛泛谈“长上下文很重要”,直接把团队在真实产品里踩过的坑讲清楚了,尤其是为什么截断不行、为什么总结也不稳,以及最后为什么留下来的是一套更克制的 context + me

ECS / OSS / CDN / 云数据库一站采购,常用云资源集中选配;新用户与续费均有专场优惠,适合个人开发者与小团队长期使用。

很多人现在一提 eval,脑子里冒出来的还是老三样:题库、benchmark、离线跑分、回归测试。这个思路在过去不是错的。问题是,今天的 agent 系统已经越来越不像“一个发布后基本不动的程序”了。它会接工具、会吃上下文、会随着用户习惯漂移,甚至连 harness 自己都可能被改写。你还拿一套静态题库去盯它,基本等于

这篇文章拆的是一个很具体、也很快会变成共性的问题:当团队开始把 OpenClaw / Pi 这类 coding agent 往真实产品里塞时,真正先卡住你的,通常不是模型能力,而是 CRM、ERP、邮件、session 和 CLI 接口有没有被整理成 Agent 也能顺手工作的系统。 这场分享我挺喜欢,因为它没继续停在

过去一段时间,Claude Code 在能力层面没让我失望,让我反复爆粗的一直是账号层。 不是模型不够强,不是终端不好用,也不是 Agent 跑不起来。是你刚把工作流磨顺,准备狠狠干一票,官方账号那边给你来一套 KYC、风控、限速,甚至莫名...

Sentra 的创始人 Ashwin Gopalan 写了一篇一年总结,叫 What Building a Company Brain over the last Year Taught Me。我看完之后憋了一晚上,今天把感受写下来。 文章...

很多人第一次用 Claude Code,停留在两个动作:提问,然后 `/clear`。 这当然能用,但你会把它当成一个会写代码的聊天框,而不是一个正在成型的终端工作台。 如果你最近看到 Claude Code 的命令越来越多,甚至开始出现 `/agents`、`/hooks`、`/plugin`、`/chrome`、`
选 Dense 还是选 MoE?这个问题在 2025 年之后已经不怎么争议了——大多数顶级闭源模型(GPT-4 系列、Gemini、DeepSeek-V3)都用了 MoE。但这不意味着 Dense 没用了。两种架构各有清晰的能力边界,选错架构的代价远大于选错模型大小。 Dense 模型就是传统的 Transformer

Agent 有个老问题:它知道怎么写代码、怎么查资料、怎么调用工具,但它不知道你自己的东西在哪里。 我说的不是联网搜索——Google 和 Bing 它已经会用了。我说的是你自己沉淀下来的那堆 Markdown:项目文档、SOP、会议纪要、故障排查记录、个人笔记。这些东西分散在十几个目录里,几百个 `.md` 文件,A

> 视频来源:
这一周最值得记住的,不是哪家模型又发了一个新版本,也不是哪家厂商又多说了几句 Agent 愿景。 真正变硬的一条线,是 Agent 开始全面撞上生产现实。算力不够,订阅收紧,漏洞变成供应链入口,观测和权限开始补票,平台厂商也不再只卖“更聪明”,而是在卖“更稳、更可控、更能接进现有系统”。 如果把这一周的 RSS 原料压

AI Agent 的终极形态不是单个 Agent 多强,是一群 Agent 怎么协作,以及它们共同积累的知识怎么不丢失。 Hermes 解决知识积累用的是 LLM Wiki 模式——用 LLM 做蒸馏引擎,把原始信息压成可检索的结构化知识。解决多 Agent 协作用的是 Maestro-Worker 架构——一个指挥、
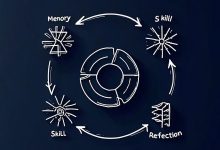
AI Agent 的核心差异不在于模型能力,在于记忆怎么管、技能怎么长。OpenClaw 是你教它做事,Hermes 是它自己在工作中学会做事。这个区别看起来小,跑 30 天后效果天差地别。 我花了三周读了 20 多篇 Hermes Agent 深度资料,做了交叉蒸馏。这篇把核心发现摊开讲:三代 AI 工具的本质差异、
这一周最值得记住的,不是又多了几个 Agent SDK,也不是哪家模型又把能力榜单往前推了一格。 真正的变化是,AI Agent 这条线开始从“能不能做更多事”,转向“谁敢把它放进真实系统里”。安全、身份校验、可审计 harness、生产级沙箱、策略透明度,这些过去常被当成配套件的东西,这一周开始越来越像主产品。 换句

> 原始文件:

最近一年做 Agent 的人,几乎都会在同一个地方反复撞墙: 模型越来越强,工具链越来越长,但对话一断、会话一换,系统就像“失忆”一样,重新变回一个陌生助手。 很多团队把这个问题当成“再接个向量库”就能解决的工程细节。看完这期视频后,我反而更确定: 真正的分水岭,不在“有没有记忆”,而在“你把记忆当成什么”。 是把它当

> 来源视频:**《谷歌 Gemma 4 最强的,不只是开源:接进小龙虾后,我终于明白本地模型真正该干什么》** > 频道:灵姐说AI | Ling Talk AI > 视频链接:https://www.youtube.com/watch?v=xK7UTN64olM width="100%" height="480"
`gbrain` 这套系统最值得分析的地方,不是“它能存记忆”,而是它把“记忆”拆成了三层彼此配合的工程结构:**可读的 Markdown 脑仓、可检索的 Postgres 索引层、可持续写入的 Agent 工作流**。这三层缺一不可。 很多项目把“长期记忆”理解成向量库:把历史内容切块、嵌入、召回,然后让模型在回答时

当很多人还在把 Agent 理解成“更复杂一点的 Prompt + Workflow”时,Anthropic 已经开始往另一条路上走了。Claude Managed Agents 的真正意义,落点不在于它把长任务、沙盒、记忆、多智能体协作这些能力打包成了一个新产品,真正关键的是它在重写整个问题的层级:**Agent 的

最近围绕 Claude Code 记忆系统的几篇文章,让我重新认真想了一遍一个其实已经被说滥、但直到今天仍然没有被真正说清的问题:大模型为什么需要记忆? 表面看,这像一个早就有标准答案的问题。模型上下文有限,所以要把过去的信息存起来;用户会...

 Toy
Toy





 Codex CLI 深度
Codex CLI 深度 AI 模型横评
AI 模型横评 AI Agent 框架
AI Agent 框架 Claude Code 订阅生存指南
Claude Code 订阅生存指南