
OpenSpec:给 AI 写代码这件事加一层"规格说明书"的逻辑
**什么改变了我的想法?** 以前我认为"规格说明书"这种东西是给大团队、正式项目用的,个人用 AI 写代码根本不需要这套流程。看完这个视频我意识到,恰恰因为 AI 写代码时的"自行补全"倾向太强,你反而更需要一个清晰的规格来约束它,否则它在每个模糊点上替你做决定,最后出来的东西跟你想的差很远。 **如果只记住一件事:


**什么改变了我的想法?** 以前我认为"规格说明书"这种东西是给大团队、正式项目用的,个人用 AI 写代码根本不需要这套流程。看完这个视频我意识到,恰恰因为 AI 写代码时的"自行补全"倾向太强,你反而更需要一个清晰的规格来约束它,否则它在每个模糊点上替你做决定,最后出来的东西跟你想的差很远。 **如果只记住一件事:

这篇分享最有价值的地方,不是又一次鼓吹 AI 写代码,而是把一个更容易被忽略的事实说透了:在大型代码库里,真正提升产出的常常不是生成能力,而是理解能力。 本文整理自 Sentry 工程师 Priscila Andre de Oliveira 在 AI Engineer 活动上的一场分享。她讲的不是“如何用 AI 一把梭

ECS / OSS / CDN / 云数据库一站采购,常用云资源集中选配;新用户与续费均有专场优惠,适合个人开发者与小团队长期使用。

这期视频表面上在讲 AI agent 的四种记忆,真正有价值的地方是它把今天已经落地的几套工程做法放进了同一张图里:上下文窗口负责眼前,Claude.md 这类项目文档负责常识,skills 负责做事的方法,跨会话记忆才负责真正意义上的“越用越熟”。原视频:https://www.youtube.com/watch?v
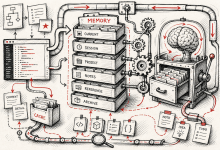
每次新开一个 Claude Code 会话,上下文窗口是空的。你之前告诉它的事情,它全忘了。 这不是 bug,是设计。问题在于,每次重新解释同一套规则,实在太麻烦。 Claude Code 提供了两套机制来解决这个问题:你自己写的 CLAU...

以前,一个非技术创始人想做一个产品,最少要三件事:找技术联创、融资、等工程师。这个周期动辄半年。 现在,他只需要打开 Claude Code,用自然语言描述需求,几天后就有一个能跑的原型。 Anthropic 最近发布了一份创业手册,讲了这个时代创业的新规则。但整份手册里最反直觉的观点不是"AI 让构建变容易了",而是
一期讲 Karpathy 式 LLM Wiki 的视频实操:三个文件夹、一个 Claude MD、按月 health check,让 AI 当知识库管理员,而不是继续让人自己维护插件栈。 本文整理自 Systems Made Better 这期视频。 它真正有价值的地方,不是再教你做一个更花哨的笔记系统,而是把知识库维

过去两年,大家讲 AI 编程,最常见的词是 prompt engineering、context engineering。现在又冒出一个新词:agent harness。词一多,概念就容易乱。Caleb Writes Code 这期 8 分钟短视频,讲的其实不是一个新黑话,而是一个很现实的工程分层:当任务变长、上下文会

最近招聘市场冒出一个被反复提起的岗位——FDE,Forward Deployed Engineer,中文译作”前线部署工程师”或”驻场交付工程师”。Indeed 的数据显示,2025 年前 9...
软件工程里有一个老规律:每当一种新形态的应用大规模出现,先解决”看得见”问题的基础设施就会成为事实标准。Web 时代是 New Relic 和 Datadog,移动时代是 Crashlytics,云原生时代是 Pro...

最近关于 AI 编程的讨论,已经从“会不会写代码”转向“怎样把一个不稳定的智能体放进可控的工程系统里”。Karpathy 这场新对谈把 software 3.0、可验证性、jagged intelligence 和 agentic engineering 之间的关系讲得更清楚了。

Transformer 刚出来时,很多人把注意力都放在 self-attention 上。那当然没错,因为它确实重新定义了模型怎么看上下文。但如果只盯着 attention,你会漏掉另一个同样关键的问题:模型怎么知道词序? 这是我看完这期视频后最强烈的感受。Transformer 的突破,不只是让每个词都能看见别的词,

软件模型有过一个很长的阶段:它们能读句子,却不太会“理解句子”。问题不在词表,也不完全在参数规模,而在于早期模型看待语言的方式太像流水线——前一个词处理完,才能轮到后一个词。这样一来,句子一长,前面的信息就会慢慢变模糊。 这就是我看完这期视频后最想记住的一点:Transformer 真正改变局面的地方,不是简单把模型做

自然语言天生有歧义。 "The detective followed the spy with binoculars." 这句话有两个完全合理的理解:侦探拿着望远镜跟踪间谍,或者间谍带着望远镜刚好被侦探跟上了。人脑能瞬间意识到两种可能,但早期的 AI 模型做不到——它只会 picks up 其中一种,另一种直接丢掉。
软件开发里,大家最熟悉的词可能还是 agent。 但最近两年,另一个词开始频繁冒出来:harness。 这个词不好翻。按字面,它是“安全带”或者“束具”。不过放到 AI 工程里,我觉得它更像一层“驯化外壳”——不是替代模型,而是把一个不稳定、不可预测、还经常会撒谎的模型,拴到一个稳定、可验证、可以控的运行环境上。 这篇

很多人第一次打开 Claude Code,最紧张的地方往往不是功能不会用,而是不知道第一句话该怎么说。这个视频其实很短,讲的也不是复杂技巧,但它点醒了一个很容易被忽略的问题:**Claude Code 的第一条 prompt,重点从来不在“修辞”,重点在你到底有没有把任务边界、风险偏好和执行节奏交代清楚。** 这类入门

本文整理自 Nate B Jones 一期关于企业 AI 变化的周观察。它表面上讲的是五条 AI 新闻,真正更值得看的是一个更底层的变化:企业正在把 AI 从聊天工具,改造成能接手真实工作流的执行者。

这篇文章想聊的,是一个越来越不方便直说、但迟早要面对的现实。AI 当然在提高效率,可它也在制造一种很温柔、很隐蔽、很容易被误判成“进步”的退化。被削弱的,不是手速,不是信息量,不是表面产出,受伤最深的是思考、表达、搜索、判断、学习这些原本该越练越强的基本能力。 最近几年最流行的一句话之一,是“不会用 AI 的人会被淘汰

本文整理自 AI Engineer 对 Intercom 工程负责人 Brian Scanlan 的分享。文章重点不只放在 Claude Code 和吞吐量翻倍,而是去看更关键的一层:当一家公司把 AI 接进主生产系统后,工程团队的分工、评价标准、平台能力和组织权力会怎样一起被重写。原视频:https://www.youtube.com/watch?v=4_VQBbs2iQA

这篇内容最值得看的地方,是它把视角直接抬到了组织层。Mike Spitz 没沿着“工程师配上 AI 之后效率更高”这条熟悉叙事往下讲,他干脆换了问题本身,从“如何让工程师产出更多”切到“如何让 agent 在组织里跑得更快”。问题一换,站会、Sprint Planning、Retrospective、代码评审分工、QA

过去一周,AI Agent 圈一口气出了五个”记忆”相关开源项目。腾讯、盛大、字节、矩阵起源、上海交大联合,都在抢同一个心智位——「让 Agent 不再是金鱼脑」。 我把五个项目都摸了一遍,包括论文、第三方解读、工程...

 Toy
Toy





 Codex CLI 深度
Codex CLI 深度 AI 模型横评
AI 模型横评 AI Agent 框架
AI Agent 框架 Claude Code 订阅生存指南
Claude Code 订阅生存指南