


写过几年代码评审工具的人都知道,PR Review 真正的瓶颈不是 LLM 的输出能力,而是 LLM 看不见的上下文——一个改动在跨文件、跨模块、跨服务之后真正影响了什么。
最近这一年,AI Code Review 的产品越冒越多:PR-Agent、CodeRabbit、Qodo、GitHub Copilot Review 都在卷”评论质量”。底层分析能力的分层共识也开始浮现——Semgrep 当规则层,SCIP 当导航层,Joern 或 CodeQL 当程序理解层,LLM 只做最后的判断。这个分层不算新,问题是落地时怎么组合。

最近行业里冒出来一个新组合:Joern 的代码属性图(CPG)+ MCP 协议,号称给 LLM 喂”程序的真实结构”。有个开源项目叫 codebadger,把 Joern 包成 MCP server,论文已经被 ICSE 2026 接收。我跟着这条线琢磨了几天,得出一个反直觉结论:CPG 不能建在 PR 分支上,只能建在 master 上;而且真正能拉开差距的不是 CPG 工具本身,是上层的业务规则库。
下面把这个判断拆开讲。
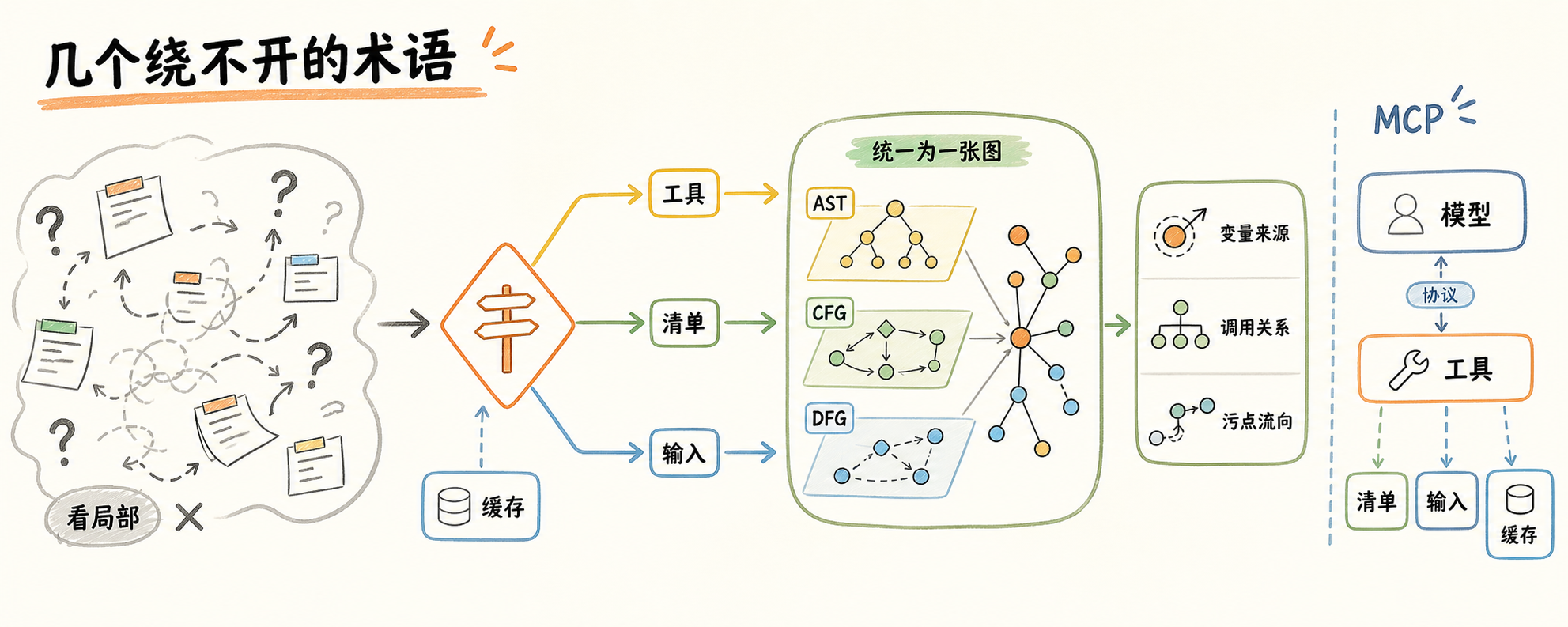
几个绕不开的术语
CPG(Code Property Graph):把代码同时表达成 AST、控制流图(CFG)、数据流图(DFG)三种结构,存成一个图。Joern 是最有名的实现,源头是德国波鸿鲁尔大学的论文 Modeling and Discovering Vulnerabilities with Code Property Graphs。它能回答”这个变量从哪流到哪””这个方法谁调用了它””这段污点输入能不能到达某个 sink”——这些用普通 grep 或 LSP 都做不了。
MCP(Model Context Protocol):Anthropic 推的协议,给 LLM 接外部工具用。MCP server 暴露一组工具,client 端的 LLM 自己决定什么时候调哪个。codebadger 干的事就是把 Joern 的 CPG 查询能力封装成 MCP 工具。
codebadger:Lekssays 开源的 Joern MCP server,工具列表包括 CPG 生命周期管理、代码浏览(list_methods/get_call_graph)、语义分析(get_cfg/find_taint_flows/run_cpgql_query)、以及一组针对 C/C++ 的漏洞检测器(UAF/double-free/null-deref/command_injection 等)。后端是 Postgres + Redis + 磁盘缓存。
容易被误解的点是两个。CPG 不是 LSP 增强版——LSP/SCIP 做的是”跳定义、找引用”,是导航层;CPG 做的是”数据流、控制流、污点传播”,是语义层。导航层一秒返回,语义层经常要分钟级。两者不能互换。
Joern 的成本不便宜。一个 10 万行规模的 Java 仓库构建一份 CPG 要 5 到 15 分钟,常驻内存 2-4GB。对比 SCIP 索引同样规模的仓库一般在 30 秒以内,Tree-sitter 解析单文件是毫秒级。这个数量级差异决定了上层架构必须怎么设计——5-15 分钟意味着这件事不可能放在 PR 同步链路上,必须异步、必须缓存、必须复用。
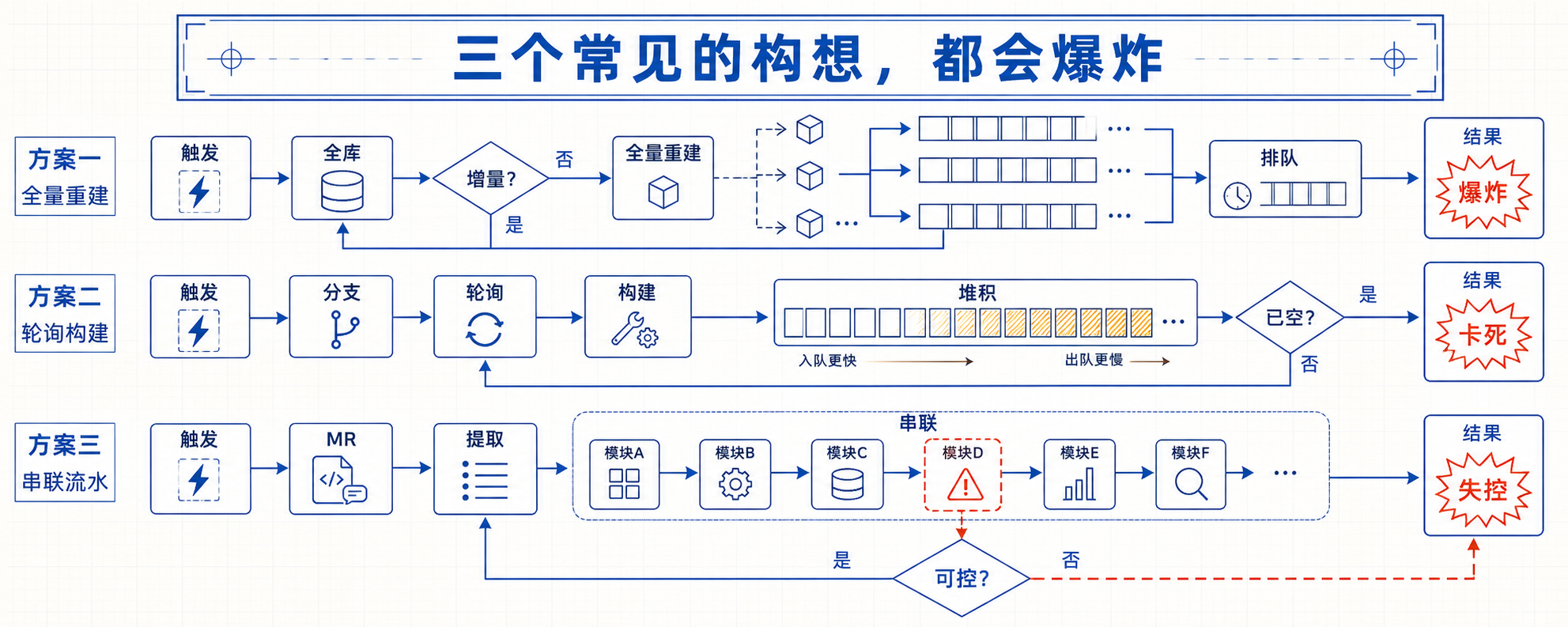
三个常见的构想,都会爆炸
我见过的初始构想往往是这样的:MCP 后端维护所有仓库 + 定时拉所有分支代码 + MR 触发提取 diff 调 MCP + 用 LangChain 串起来。听起来挺合理,每一步都站得住,但放在一起就走不通。
坑一:定时拉所有分支生成 CPG,会指数级爆炸。
设想有 20 个仓库,每个仓库平均 8 个活跃分支,那就是 160 份 CPG。按 10 万行规模算,每份 5-15 分钟构建、2-4GB 内存。一台 64GB 内存的机器最多并发 12 份 CPG 构建,串行跑完一轮要 1-2 小时。而 Joern 不支持真正的增量更新——代码改一行也要全量重建。结果是:定时任务还没跑完一轮,下一轮已经堆积起来了,CPG 永远是过期的。
业界跑增量 CPG 的论文有几篇,但开源实现里没有一个稳定的。Joern 团队也明说短期不会做增量。这条路在工程上就是死的。
坑二:在 PR 分支上建 CPG,是错位需求。
CPG 的价值是”已有代码的调用链和数据流”——查 source 在哪、sink 在哪、谁调用了谁。这些信息在 target 分支(通常是 main)上就已经存在了,根本不需要 PR 分支。PR 分支变动太快,缓存命中率几乎为零,build 成本却一分不少。在 PR 分支建 CPG 等于每次评审都付一次全量构建的钱。
坑三:用 LangChain 包 MCP,是过度抽象。
MCP 协议本身就是稳定接口——Anthropic 官方有 Python 和 TypeScript 的 mcp client SDK,加 Anthropic SDK 几百行代码就能跑通”LLM + MCP tool + agent loop”。LangChain 最近一两年抽象层叠太厚,把简单的事变复杂,还绑死自己的 chain 抽象。MCP 这一层不需要这种中介。
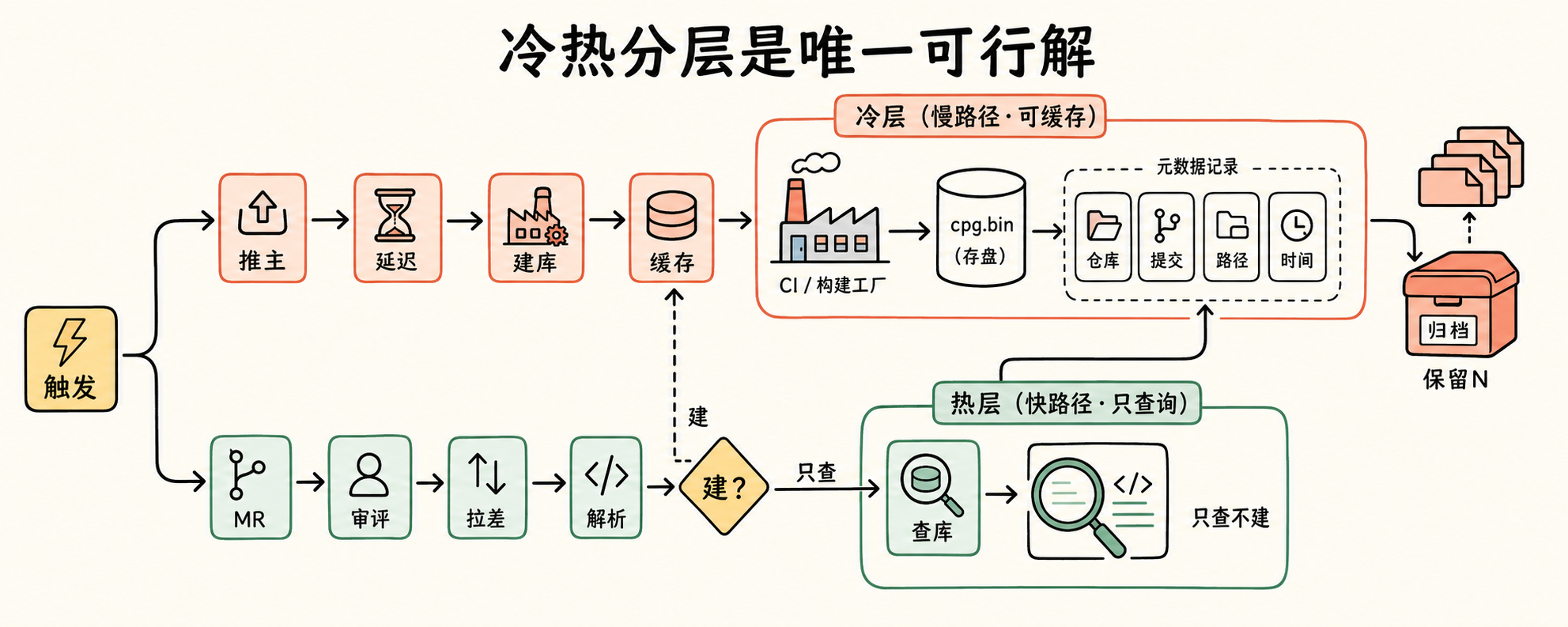
冷热分层是唯一可行解
把上面三个坑反过来想:CPG 既然贵又改不动,那就让它慢慢建、长期用;评审既然要求快,那就让它只查不建。这就是冷热分层。
冷层(slow path)——只在 push 到 master 时触发,debounce 5-10 分钟避免抖动。Joern build CPG → cpg.bin 存盘 + Postgres 记录 metadata(repo, commit_sha, cpg_path, built_at)。保留最近 N 个版本,老的归档。这一层是稳定的、可缓存的”语义查询库”,不参与任何 PR 评审的实时链路。
热层(fast path)——MR webhook 触发,拉 diff,Tree-sitter 解析提取 changed_symbols,按 MODIFIED/DELETED/ADDED/FIELD 分类。每类走不同的查询路径,全程毫秒级响应。
关键的 caveat 是:PR 里新增的方法在 master CPG 里根本不存在。这不是 bug,是边界。处理方式按变更类型分类:
- MODIFIED(签名未变):master CPG 查影响面、调用图、数据流
- DELETED:master CPG 查谁还在调它,找出潜在编译失败和断链
- ADDED:CPG 查不到,走 Tree-sitter + LLM 处理 AST
- FIELD/CONST 变更:master CPG 查所有引用点
ADDED 类型有个有意思的细节:新方法本身 CPG 查不到,但如果它调用了 master 已有的危险 API,那是 CPG 能管的——查 callees 落在哪个 sink。所以”CPG 盲区”不是绝对的,要看具体什么 case。
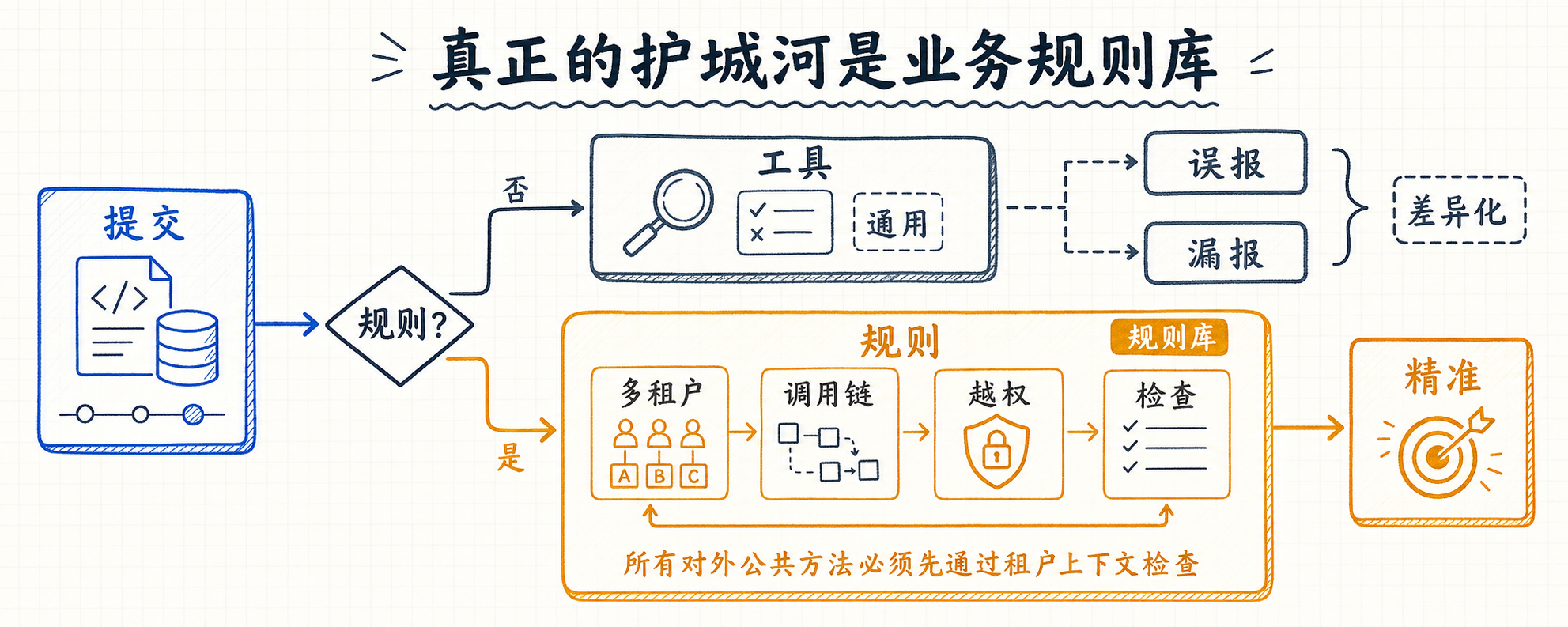
真正的护城河是业务规则库
到这里架构问题解决了,但还有一个更重要的问题:为什么我要自己搞这一套?CodeRabbit 和 Copilot Review 不香吗?
我的答案是:通用 review 工具卷不出差异化,业务规则才是。
任何公司自己的代码库里都堆着一批”必须遵守、但别人不知道”的规则。举几个具体场景:
多租户系统——所有 Controller 的 public 方法都必须先调 TenantContext.check(),没调就是越权漏洞。这条规则用 Semgrep 写表达力不够(要看跨方法调用链),用 LLM 直接问漏报率高(容易被”看着像在做检查”的代码骗)。但用 CPGQL 写一条查询,几行就搞定:
val endpoints = cpg.method
.where(_.annotation.name("RestController"))
.isPublic
endpoints
.whereNot(_.call.name(".*[Tt]enant.*[Cc]heck.*"))
.whereNot(_.call.name(".*assertOwn.*"))
.map(m => (m.fullName, m.lineNumber, m.filename))
消息协议向后兼容——MQTT topic 名一旦发布给设备端,删了就是事故。代码里 publish topic 的地方分布在几十个 service 里,PR 时 reviewer 没法肉眼追全。CPG 一查,所有 publisher 调用链清清楚楚。
远程指令鉴权——所有”会让远端设备执行动作”的 handler 都必须经过特定的权限校验和审计日志。这条规则人写 review 三个里漏一个,CPG 能精确列出所有 handler 函数。
升级触发路径——OTA 链路涉及版本检查、批次控制、回滚策略,任何一条调用链绕开这些环节都是定时炸弹。
这些规则的共性是:它们存在于团队的 tribal knowledge 里,不在 GitHub Copilot 的训练集里,也不在 CodeRabbit 的通用 prompt 里。把它们一条条写成 CPGQL 查询、封装成 MCP 工具——这才是别人抄不走的东西。
把规则做成 MCP 工具的好处是:LLM 不需要会写 CPGQL,只需要选工具、解释命中、判严重程度。CPGQL 的复杂度沉淀在工具实现里,LLM 看到的是高层接口。harness 越薄越好,skill 越厚越好——通用语义工具是 skill,业务规则工具也是 skill,LLM 只是调度器。
自己写还是 fork codebadger
工程选型:通用语义工具(list_methods、get_call_graph、find_taint_flows 那一堆)我应该自己包 Joern 还是用 codebadger?
我的判断是 fork codebadger。理由很直接:
- codebadger 已经实现了 30 多个通用工具,从零写至少两人月
- Joern server 池、LRU 复用、reaper 睡眠唤醒这套基础设施 codebadger 已经写过
- C/C++ 漏洞检测器我用不上但也不碍事
- 业务规则工具是要自己加的,但加在 fork 里比从零搭框架快得多
codebadger 唯一需要警惕的边界是:它是被动的查询服务,不是仓库管理器。CPG 按 content hash 缓存,没有 repo/branch 概念——这是它简洁的地方,也意味着调度逻辑、版本管理、增量策略都得自己在外层 harness 里实现。把它当语义查询引擎用,别指望它管仓库。
Stage 0 优先于 Stage 1
最后一条原则,是我反复强调但最容易被绕过的:做任何架构决策之前,先建立评估闭环。
我看过太多团队上来就堆工具——先接 Semgrep,再上 SCIP,再调 CodeQL——三个月之后没人说得清”到底有没有比纯 LLM 强”。原因是没有 benchmark。
Stage 0 应该是这样的:
- 拉过去 6 个月的真实 PR,挑出 30-50 个
- 关联工单系统的事故记录,标注哪些 PR 后来出过线上问题
- 用纯 LLM 跑一遍,记录命中和漏报
- 加上 Semgrep 再跑,看增量
- 加上 SCIP 跨文件上下文,看增量
- 加上 CPG 查询,看增量
每一层加进去如果命中率涨不动,就别加。命中率涨了但误报飙升,权衡。这套 benchmark 跑一周,比什么架构辩论都有用。
这不是”先评估再实现”的形式主义——评估本身就是产品的核心组件。AI Code Review 上线之后,每周 PR 评审命中率、误报率、被采纳率都要监控。没有这套数据,模型升级和规则迭代就是瞎调。
收束
回到开头那个反直觉的判断:CPG 建在 master 上、PR 分支只走 Tree-sitter + LLM。看起来”覆盖不全”,但实际上是把贵的东西放到能复用的地方、把便宜的东西放到要响应快的地方。
如果你也在搭 AI Code Review,可以从最小一步开始:fork codebadger,跑通本地 MCP server,挑团队里最痛的一条业务规则写成 CPGQL,看看能不能命中过去半年的真实事故。能命中,就有继续投入的根据;不能命中,再去想是规则没写对还是 CPG 工具不够用。
别从 LangChain 开始。
参考
- GitHub – Lekssays/codebadger — Joern MCP server 实现
- Bridging Code Property Graphs and Language Models for Program Analysis — ICSE 2026 论文
- Joern 官方文档 — CPG 与 CPGQL 入门
- Model Context Protocol — Anthropic MCP 协议规范












 AI周刊:大模型、智能体与产业动态追踪
AI周刊:大模型、智能体与产业动态追踪 程序员数学扫盲课
程序员数学扫盲课 冲浪推荐:AI工具与技术精选导航
冲浪推荐:AI工具与技术精选导航