


自己玩 VPS 的人迟早会遇到一个问题:手里 5 台机器要监控,得装一个面板把它们串起来;问题是面板自己也得跑在一台机器上,那这台机器谁来监控?再开第 7 台吗?
这就是监控者悖论。哪吒探针、Uptime Kuma 都绕不开这一层:Dashboard 是有状态的服务,要 VPS、要数据库、要反代、要 HTTPS 证书,要定期升级。你给 5 台机器装监控,最后变成在管 6 台机器。

CF-Server-Monitor 用一个偏方法论的方式解掉了这一层——把面板整个搬到 Cloudflare Workers 上。没有面板服务器,没有持久进程,没有要登录维护的”第 6 台机器”。演示站在这里:https://tz.dashdeep.dpdns.org/。
我看了几天,觉得值得介绍一下。
这是个什么项目
简单说:一个跑在 Cloudflare Workers + D1 上的服务器探针监控系统。每台被监控的机器上跑一个 shell 脚本(Alpine/OpenWrt/Windows 也支持),按设定间隔把 CPU、内存、磁盘、网络、进程数、连接数、负载、月流量、电信/联通/移动/字节四向 ping 上报给 Worker,Worker 写 D1,前端拉数据出图。
仓库目前 256 stars / 153 forks,2026 年 5 月底建仓,到现在一个多月跑到 V2.6.8,更新频率挺猛。作者署名 huilang-me。
它不是 Uptime Kuma 那种 SaaS 式外挂监控——那种是从外部拨号探活。这是反过来的:探针装在你机器上,主动往面板推数据,跟哪吒探针、ServerStatus 一个路数。差别只在面板这一头跑在哪。
为什么”Workers 当面板”是个聪明取舍
你也许会问:面板就一个网页 + 一个数据接收 API,为什么是个值得讨论的设计选择?
因为这个面板有几个特殊属性:
- 写入频繁:每台机器 60 秒上报一次,10 台机器一天就是 14400 次写入
- 读取要实时:用户打开页面想立刻看到最新数据,不能轮询到 30 秒前
- 数据要留:1/3/6/12/24 小时历史曲线,得有时序存储
- 要全球可达:你的 VPS 散在东京、洛杉矶、香港,监控面板要让它们都能低延迟上报
放到一台 VPS 上,前面三个都不难,第四个开始头疼——一台在东京的面板,你的洛杉矶机器要跨太平洋上报;想要”哪里都快”就得多区域部署。但这套 Workers + D1 的组合是天然全球分布的:边缘节点接 HTTP,D1 自己做读写分离和异地复制,开发者不写一行代码就拿到了多地域低延迟。
更扎心的一点:全部跑在免费额度里。
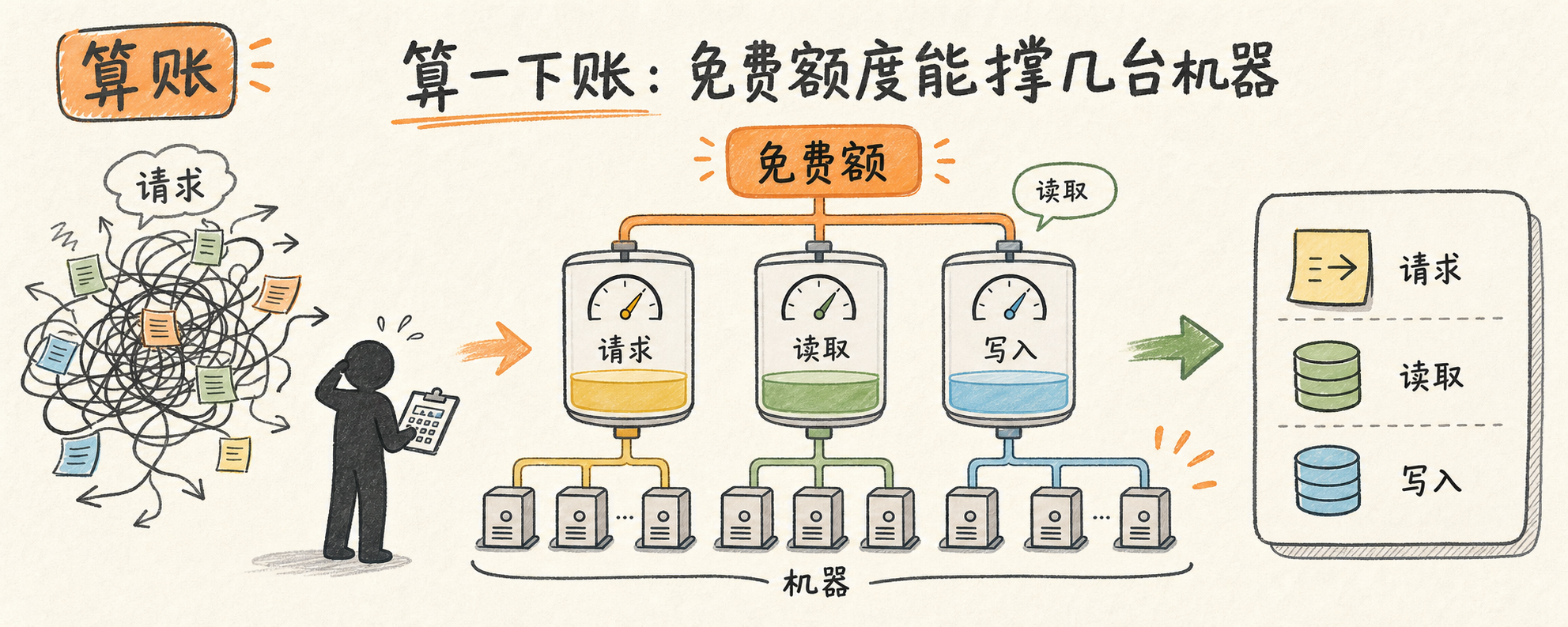
算一下账:免费额度能撑几台机器
Cloudflare 免费额度(官方文档):
- Workers:100K 请求/天
- D1:500 万行读取/天、10 万行写入/天
- Durable Objects:100K 请求/天
业界常识:D1 这种”小流量起步、按量计费”的边缘数据库,写入是最贵的一档;10 万行写入/天听起来挺多,分到 60 秒一次的探针上报上其实很快见底——一台机器一天 1440 次写入,纯写满了能跑 69 台机器。
V2.6.0 的更新日志里有一句话:”降低了 50% 的 D1 写入消耗,强烈建议升级”。翻译成 so-what:同样 10 万行写入额度,能监控的机器数翻倍到 ~140 台。对个人玩家、小团队 SRE 来说,这个上限基本永远碰不到。
对比下其他方案的真实成本:
| 方案 | 面板托管 | 月成本 | 维护负担 |
|---|---|---|---|
| 哪吒探针 | 自建 VPS | 香港 2H2G ≈ 20 元/月 | 自己装、自己升级、自己 HTTPS |
| Uptime Kuma | 自建 VPS | 同上 | 同上 |
| UptimeRobot 免费版 | SaaS | 0 元 | 但只能 50 个监控点 + 5 分钟间隔 |
| BetterStack/Pingdom | SaaS | $20+/月 | 0 维护,但贵 |
| CF-Server-Monitor | Cloudflare Workers | 0 元 | 改一次 git push 自动部署 |
20 元/月一年 240 元,对个人 VPS 玩家不是大钱,但省掉的不只是钱,是那台多余 VPS 的存在感——你不用再操心面板这台机器自己挂没挂、续费没续费、升级会不会炸。
实时刷新这一块的小工艺
很多人写监控会卡在”实时”两个字上。轮询每 5 秒拉一次,浪费带宽还慢半拍;做长轮询/SSE 又得长连接,免费 Worker 不友好。
这个项目用了一个 Cloudflare 自家的组件:Durable Objects + WebSocket。Durable Objects 是 CF 的”有状态边缘对象”,每个 Object 有自己的内存和持久存储;项目把”接收探针上报、广播给所有在线浏览器”的逻辑放进 DO 里,浏览器开 WebSocket 跟它对话。
效果是:探针推一次,所有打开页面的人立刻看到新数据,零轮询。这种实现在自建 VPS 上要装 Redis/Nats 做 pub/sub,在 Workers 上是开箱的。
V2.5.0 的更新日志原话:”在不占用 D1 消耗的情况下,前端 WebSocket 实时刷新数据”。这句里”不占用 D1″很关键——实时推送走 DO 自己的额度(100K 请求/天),跟 D1 的 10 万行写入分开计算,两个额度都用得上。
几个细节加分项
我翻了一下 README 和 changelog,有几个东西值得单独点名:
- JWT + Turnstile 双层认证:登录走 JWT,探针上报走 Turnstile 防刷。免费监控最怕被薅,这块作者想过
- 拖拽排序:管理后台直接拖,比改配置文件友好得多
- 服务器隐藏:可以把某台机器对未登录用户藏起来。你给朋友看面板时,敏感的机器别让人看见
- 月流量统计:自定义重置日(1-31 号),按月计算上下行;适合那些”每月 1T 流量”配额制的 VPS
- 流量校正:可以手动直接设置当月已用流量(GB),用来对齐机器中途装的探针或者重装系统后的统计断点
- 延迟追踪:内置电信/联通/移动/字节的 ping 节点,看的是国内访问质量,不是简单 ping 自己 ifconfig.me
这些都是用过监控面板的人才会在乎的细节。一看就知道作者自己在用。
适合谁,不适合谁
适合:
- 手里有 3-50 台 VPS 的个人玩家
- 国内小团队、独立开发者,想给自己几台机器做基础观测
- 不想再为”监控面板这台机器”付钱付精力的人
- 已经在用 Cloudflare 的人(账号现成,上手快)
不适合:
- 上百台机器的生产环境——免费额度撑不住,付费一档之后性价比反而不如 Prometheus 自建
- 需要复杂告警规则、SLO 计算、PromQL 查询的场景——这是 Grafana 的活
- 不想绑 Cloudflare 的人——整个数据存储和入口都在 CF,迁出成本就是重写
- 国内业务要无墙可达——Workers 子域名(
*.workers.dev)在国内访问不稳,作者也建议绑自己域名
怎么开始
最省事的路径是 README 里写的”方式一”:Fork 仓库 → Cloudflare Workers 连接 GitHub → 填一个 API_SECRET 环境变量 → 部署完成。整个过程不到 10 分钟。后续升级就一个 Sync fork,Workers 自动重新构建。
探针那一头一行 curl 命令:
curl -sL https://你的项目.workers.dev/install.sh | bash -s install \
-id=<SERVER_ID> -secret=<SECRET> -url=<WORKER_URL>
Alpine、OpenWrt、Windows(pyw 脚本)都支持,覆盖了大部分小机器的场景。
收束
监控这件事的核心问题不是”看不看得到数据”,而是”我愿不愿意为看到这些数据再多养一台机器”。CF-Server-Monitor 这个项目的价值,本质上是把这个”再多养一台”的成本压到了零——不是优惠到零,是结构上就没有。
哪吒探针之类的方案技术上更成熟、功能更全,但在”个人玩家 / 小团队 / 不到 50 台机器”这个区段里,这种 Serverless 思路确实是当下最合理的解。值得 fork 一份,给自己的小破服务器装一下。
仓库地址:https://github.com/huilang-me/CF-Server-Monitor,演示:https://tz.dashdeep.dpdns.org/。










 AI周刊:大模型、智能体与产业动态追踪
AI周刊:大模型、智能体与产业动态追踪 程序员数学扫盲课
程序员数学扫盲课 冲浪推荐:AI工具与技术精选导航
冲浪推荐:AI工具与技术精选导航