Claude执行速度慢引热议,用户反馈耗时过长
在Linux.do论坛上,用户反映AI模型Claude执行速度缓慢,修改代码任务需数分钟,修改功能甚至耗时数小时。多位用户参与讨论,探讨是否使用方法不当。这一现象引发对AI工具性能优化的关注,可能影响用户体验和行业应用。专家指出,速度瓶颈可...
在Linux.do论坛上,用户反映AI模型Claude执行速度缓慢,修改代码任务需数分钟,修改功能甚至耗时数小时。多位用户参与讨论,探讨是否使用方法不当。这一现象引发对AI工具性能优化的关注,可能影响用户体验和行业应用。专家指出,速度瓶颈可...
本文探讨了豆包AI助手在科学调查中的实际应用案例,作者全程利用豆包内置语音转文字系统辅助水中小动物类群丰富度调查,展示了AI工具在科研创作中的高效性。同时,文章揭示了用户从豆包转向其他工具后回归的现象,反映了AI助手领域的竞争动态和用户体验...
据用户反馈,ChatGPT的flash cards样式测验功能疑似被OpenAI移除,用户无法再调用此学习工具。这一变化引发社区广泛讨论,涉及AI教育功能的实用性和用户体验。在Linux.do论坛上,相关话题已有8个帖子和5位参与者参与,反...
本文深入剖析了PGP加密技术存在的核心问题,包括荒谬的复杂性、瑞士军刀式设计导致的向后兼容困境、糟糕的用户体验、长期安全隐患、破损的身份验证机制、元数据泄露风险、缺乏前向保密性、密钥管理笨拙以及代码质量低劣。针对这些问题,文章提出了实用解决...
用户在网页版Gemini中使用“过往对话记录”记忆功能时,发现回答变得异常,似乎过度依赖记忆导致回答被带偏。关闭该功能后,回答恢复正常。这一现象揭示了AI记忆机制在个性化与准确性之间的潜在冲突,提示开发者需优化记忆算法以避免用户误解。 原文...
几年前,作者开始通过在URL末尾添加.txt来提供纯文本版本的博客文章。这种格式提供快速、简洁、可读的浏览体验,没有cookie横幅、弹出窗口或自动播放视频。文章收集了一系列支持纯文本访问的网站,如Terence Eden的博客和Darin...
Claude Code在处理包含中文字符的文件路径时,自动完成功能显示为unicode编码而非实际中文字符,严重影响中文用户使用体验。该bug已报告至GitHub,从v2.0.73版本开始出现,影响Windows和macOS系统。用户在输入...
回顾2000年代初期浏览器引入弹出广告阻止功能(如Firefox和IE)的历史,揭示如今弹出广告通过技术进化绕过浏览器防御,覆盖内容、误导用户,严重影响体验。浏览器开发者未跟上广告技术军备竞赛,呼吁重新实现Pop-up Blocking 2...
游戏设计中的三个基本场所——野外、地牢和城镇各具特色又相互依存。本文深入探讨了如何将这三者无缝整合,创造连贯且引人入胜的游戏世界。文章详细分析了野外设计中的规模与探索激励、地牢设计中的流程与挑战、城镇设计中的功能与NPC互动,以及整合策略:...
用户分享多款AI模型在开发场景中的真实体验。Codex Pro凭借独立额度和5.2 xh模型的高性能获得好评,Claude Opus却因快速达到限额而问题未解决;GPT虽慢但质量可靠,效率远超手动开发。Codex系列中,5.2版本性能下滑,...
近日,用户在Linux社区分享了一个有趣现象:在使用Google的Gemini-CLI工具时,新用户(首次使用的账号)的报错率显著低于老用户。新账号报错仅5-10次,而老账号在相同任务下报错10-15次。作者推测Google可能更注重新用户...
近日,Linux.do社区用户分享经历称,在尝试与Gemini 3探讨情绪管理及唯物主义心理学相关问题时,AI模型连续三次中断对话,不允许用户继续发言。用户推测这可能源于AI的安全协议或关键词触发机制,旨在防止潜在不当内容。该事件突显了AI...
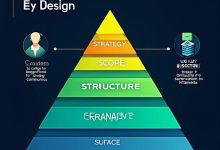
用户体验要素:五层模型 为什么这本书重要? 产品经理说:”加个功能。” 设计师说:”这样不好看。” 开发说:”实现不了。” 问题:大家说的不是一回事。 《用户体验要素》...
本文深入分析了当前主流人工智能产品存在的三大问题。首先,GPT模型在输出结果上与思考过程存在明显差异,表现为回复生硬难懂,缺乏自然流畅的表达。其次,谷歌Gemini-3在搜索和信息收集功能上表现不佳,即使通过提示词强制执行也敷衍了事,甚至提...
尽管用户已请求两年多,ChatGPT对话界面仍未显示消息时间戳,这一功能缺失给用户追踪对话历史、工作流程和法律合规带来困难。社区用户自发提出多种解决方案:在设置中添加提示让AI自动显示时间、通过Chrome控制台脚本提取隐藏的时间戳数据,以...
近日,技术社区V2EX上一则关于豆包AI的发现引发关注。有用户测试发现,在不登录状态下,豆包AI能够完整解析GitHub代码提交链接并生成详细总结;而登录后,同一请求却得到’未查询到相关信息’的回复。这一反常现象揭示...
一位用户对GLM4.7进行了实际体验测试,并与Claude Sonnet 4.5进行了对比。前端表现尚可,但稳定性不及Claude Sonnet 4.5。偶尔会出现错误,需要用户自行修改多次,排错能力不如GPT-5,但最终效果符合预期的概率...
本文分享了用户如何模仿ChatGPT的年度总结,为Gemini创建详细的年度报告提示词。提示词包括年度诗篇、三大亮点、客观数据分析(如总聊天数、高频词汇)、聊天风格总结、年度大奖颁发及用户类型成分图设计。报告形式采用Apple风格展示,具备...
在年末总结季节,用户分享使用Gemini 3 Pro编写材料的体验。用户表示,与2 Pro相比,3 Pro版本更难用,过去2 Pro只需修改两三次初稿即可使用,而3 Pro花费一天时间才勉强完成。这一反馈反映了AI模型在实际应用中的性能差异...
本文作者时隔数月再次体验AI API管理工具Newapi,发现虽然已支持查看API密钥等基础功能,但在核心的模型重定向功能上仍存在明显痛点。与竞品Onehub相比,Newapi需要用户手动完成模型映射,提交后还需再次添加到模型列表,操作流程...
 Toy
Toy





 AI周刊:大模型、智能体与产业动态追踪
AI周刊:大模型、智能体与产业动态追踪 程序员数学扫盲课
程序员数学扫盲课 冲浪推荐:AI工具与技术精选导航
冲浪推荐:AI工具与技术精选导航 Claude Code 全体系指南:AI 编程智能体实战
Claude Code 全体系指南:AI 编程智能体实战
最新评论
这篇文章写得太实用了!按照步骤一步步来,真的能从小白搭建起一个仿小红书的小程序。Cursor的AI补全功能确实大大提高了开发效率,感谢分享!
对比得很清晰。个人觉得如果只是日常聊天和简单任务,Claude 4.5的性价比更高;但如果是复杂的编程任务,GPT-5.2还是更稳定一些。希望能看到更多关于具体使用场景的对比。
开源项目的安全确实容易被忽视。这个案例提醒我们,即使是小功能也要做好权限校验。建议作者可以补充一下修复后的代码实现,让读者更清楚如何防范此类问题。
这个案例太典型了。配置错误导致的故障往往最难排查,因为看起来一切都正常。我们在生产环境也遇到过类似问题,后来引入了配置审查机制才好转。建议大家都重视配置管理!
很棒的漏洞分析!这种小号入侵的问题确实很容易被忽略。建议项目方可以增加一些风控规则,比如检测同一IP的多次注册行为。感谢分享这个案例!
FreeBSD的jail机制确实很强大,能把服务隔离得很干净。不过配置起来确实有点复杂,这篇文章把步骤写得很详细,准备按照教程试试!
实测下来确实如文章所说,规划能力有提升但偶尔会抽风。天气卡片那个案例很有意思,说明模型在理解上下文时还是会踩坑。希望后续版本能更稳定一些。
论文筛选真的是科研人员的痛点,每天arxiv上那么多新论文,手动看根本看不过来。这个工具如果能准确筛选出相关论文,能节省不少时间。感谢开源!