马斯克开源X新算法:全Transformer架构,Rust重写
马斯克团队正式开源了X平台全新的推荐算法,核心亮点在于完全基于Transformer架构,取代了旧版的手工特征工程。新算法采用与Grok相同的结构,通过Phoenix Scorer直接处理实时互动序列进行排序。技术栈全面采用Rust语言重写...
马斯克团队正式开源了X平台全新的推荐算法,核心亮点在于完全基于Transformer架构,取代了旧版的手工特征工程。新算法采用与Grok相同的结构,通过Phoenix Scorer直接处理实时互动序列进行排序。技术栈全面采用Rust语言重写...
本文介绍了名为Tauformer的新型拓扑Transformer架构,它通过图拉普拉斯导出的标量替代传统的点积注意力,将域结构直接注入模型。这种设计使KV缓存只需存储值和标量流,而非完整的键张量,实现了约50%的逐层缓存缩减。在H100上的...
自2016年以来,无论是GPT-5、Claude还是Gemini,所有主流Transformer模型均沿用单一残差连接设计 $x + F(x)$。本文深入探讨了DeepSeek提出的mHC架构,该设计大胆挑战了这一传统范式,通过拓宽残差连接...
indexTTS 2.5已在arXiv发布技术报告,显著提升了多语言覆盖范围、推理速度和语音合成整体质量。该模型基于Transformer架构,包含文本到语义(T2S)模块和非自回归语义到梅尔(S2M)模块,实现零样本神经文本到语音功能。实...
一项最新研究揭示,65%的Hacker News帖子带有负面情绪,这些帖子平均得分35.6分,比整体平均高出27%。研究基于32,000个帖子和340,000条评论,使用多个AI模型(包括DistilBERT、BERT、RoBERTa和Ll...
作者开源新型神经网络架构Fielix,以“场效应”机制替代传统注意力机制。实验显示,在27M参数模型下,Fielix初始Loss为3.0,Transformer为7.9;最终Loss Fielix为1.66,Transformer为2.59...
本文提供了AI大模型全栈工程师第9期的完整课件资源,包括视频课程和配套工具包,覆盖大模型应用开发基础、Prompt Engineering、模型微调(上下)、多模态大模型(上下)、神经网络和Transformer详解、LangChain、R...
GitHub上出现一个PR,旨在为GLM-Image适配AR模型的实现。该PR由开发者提交,获得51个赞,显示社区支持。GLM-Image是一个基于Transformer的AI图像模型,此次适配可能预示模型将扩展功能,支持更多应用场景,为未...
Trellis AI是斯坦福AI实验室的衍生公司,专注于构建AI代理以革新医疗保健访问。他们的系统自动化文档处理、预先授权和上诉流程,每年处理价值数十亿美元的治疗,覆盖全美50个州。公司由YC、General Catalyst等知名投资者支...
本文是《Karpathy神经网络零基础课程》系列文章 ← 上一篇:Karpathy神经网络06:WaveNet – 神经网络大升级 | → 下一篇:Karpathy神经网络08:Tokenizer – 为什么AI不识...
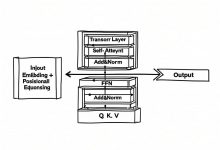
TL;DR 面试官问你Transformer原理,你能答到什么深度?本文从12个高频面试题入手,带你搞懂大模型的底层架构——不是背概念,是真正理解为什么GPT用单向注意力、LLaMA为什么选RoPE、多头注意力到底在干什么。读完这篇,你能用...

大模型面试100问:从基础到实战的完整指南 为什么需要这个系列? 大模型面试不是背八股文——面试官要的是系统性理解和实战经验。市面上的面试题要么太碎片化(100个孤立问题),要么太理论化(只讲公式不讲应用)。 这个系列不一样: ✅ 系统化:...
Andrej Karpathy推出“神经网络:从零到英雄”课程,系统讲解从反向传播到现代深度神经网络如GPT的构建过程。课程包括实践项目:micrograd、makemore语言模型、MLP、WaveNet、GPT及其Tokenizer。通...
混元Motion 1.0是一款基于Diffusion Transformer(DiT)架构与流匹配机制的十亿参数级AI模型,能从自然语言描述生成流畅自然的3D角色动画,覆盖广泛类别并无缝集成到美术管线。该模型由腾讯研发,计划于2025年12...
一位拥有13年Java开发经验的39岁开发者,近日萌生转型AI大模型开发的念头。他已系统学习机器学习、深度学习、Transformer等核心技术,虽感门槛高但充满探索热情。针对转型可行性、常见陷阱及学习路径,他向行业前辈寻求真实建议。这一经...
在Linux.do社区,用户讨论使用transformers.js运行Kokoro-82M模型实现离线Web端TTS(文本转语音)功能。用户反馈模型运行延迟较高,虽可用但体验不佳,寻求更高效的替代方案。这反映了在浏览器环境中部署大型Tran...

AI工程师转型路径:从零到生产级部署 一、问题 传统工程师的困境: – 会写代码,但不懂Transformer – 会调API,但不懂模型原理 – 会用ChatGPT,但不会训练模型 核心疑问:如何从传统...
本文探讨了如何利用Google Gemini 3.0人工智能模型拆解学术论文中的抽象方法,将其转化为具体的工程操作,以促进深度学习领域的理解。作者发现,传统论文解读方式易受原文表述影响,导致注意力分散且难以直观掌握核心概念。通过优化提示词,...
该论文系统分析了通用Transformer在复杂推理任务中的性能表现,发现其优势主要源于循环归纳偏置和强非线性组件,而非复杂架构设计。基于此,作者提出通用推理模型(URM),通过集成短卷积和截断反向传播技术,显著提升了推理能力。实验显示,U...
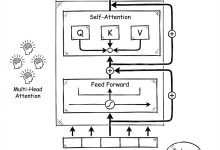
本文详细解析了Transformer模型的工作原理,包括自注意力机制、多头注意力、位置编码和编码器-解码器结构。文章通过可视化方式,帮助读者理解如何通过Query、Key和Value向量实现序列建模,以及Transformer如何优化并行训...
 Toy
Toy





 AI周刊:大模型、智能体与产业动态追踪
AI周刊:大模型、智能体与产业动态追踪 程序员数学扫盲课
程序员数学扫盲课 冲浪推荐:AI工具与技术精选导航
冲浪推荐:AI工具与技术精选导航 Claude Code 全体系指南:AI 编程智能体实战
Claude Code 全体系指南:AI 编程智能体实战
最新评论
Flash版本的响应速度确实提升明显,但我在使用中发现对中文的理解偶尔会出现一些奇怪的错误,不知道是不是普遍现象?
遇到过类似问题,最后发现是网络环境的问题。建议加一个超时重试机制的示例代码。
谢谢分享,我是通过ChatGPT的索引找到这里来的。
十年打磨一个游戏确实罕见,这种专注度在快节奏的游戏行业很难得。从Braid到The Witness,每作都是精品。
快捷键冲突是个很实际的问题,我自己也被这个问题困扰过。最后通过自定义快捷键组合解决了。
会议摘要这个功能很实用,特别是对经常需要参加长会议的人。不过三次免费使用确实有点少了。
硕士背景转AI基础设施,这个路径其实挺常见的。建议多关注底层系统知识,而不只是模型应用层面。
配置虽然简单,但建议补充一下认证和加密的注意事项,避免被中间人攻击。