
程序员数学扫盲课:10年经验程序员的数学补习指南
为什么10年经验的程序员还需要补数学? 你写了10年代码,却看不懂Redis的SINTER为什么这么快? 你做过无数次容量规划,却不知道为什么缓存命中率从90%提升到95%,性能能翻倍? 你天天用负载均衡,却不明白一致性哈希为什么能解决扩容...
为什么10年经验的程序员还需要补数学? 你写了10年代码,却看不懂Redis的SINTER为什么这么快? 你做过无数次容量规划,却不知道为什么缓存命中率从90%提升到95%,性能能翻倍? 你天天用负载均衡,却不明白一致性哈希为什么能解决扩容...
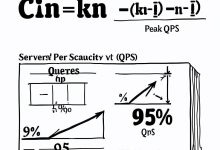
本文是《程序员数学扫盲课》系列文章 ← 上一篇:程序员数学09:信息论 – 数据压缩 TL;DR 为什么100万用户需要多少台服务器?为什么数据库连接池要设置多大?为什么缓存命中率从90%提升到95%,性能能翻倍?答案都藏在组合...
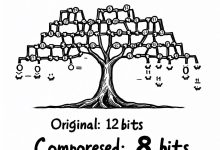
本文是《程序员数学扫盲课》系列文章 ← 上一篇:程序员数学08:哈希与模运算 – 负载均衡 | → 下一篇:程序员数学10:组合数学 – 容量规划 TL;DR 为什么ZIP能把文件压缩到原来的1/10?为什么HTTP...
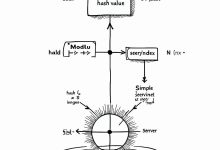
本文是《程序员数学扫盲课》系列文章 ← 上一篇:程序员数学07:线性代数 – 推荐系统 | → 下一篇:程序员数学09:信息论 – 数据压缩 TL;DR 为什么负载均衡能把请求均匀分配到服务器?为什么一致性哈希能解决...
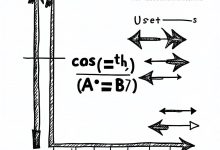
本文是《程序员数学扫盲课》系列文章 ← 上一篇:程序员数学06:统计学 – P99延迟监控 | → 下一篇:程序员数学08:哈希与模运算 – 负载均衡 TL;DR 为什么推荐系统能猜出你喜欢什么?为什么协同过滤这么准...
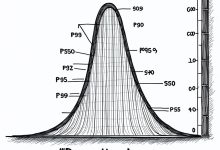
本文是《程序员数学扫盲课》系列文章 ← 上一篇:程序员数学05:概率论 – 系统可用性 | → 下一篇:程序员数学07:线性代数 – 推荐系统 TL;DR 为什么监控报警不看平均值要看P99?为什么1%的慢请求能毁掉...

本文是《程序员数学扫盲课》系列文章 ← 上一篇:程序员数学04:图论 – 微服务依赖管理 | → 下一篇:程序员数学06:统计学 – P99延迟监控 TL;DR 为什么三个99.9%的服务串联后,整体可用性只有99....
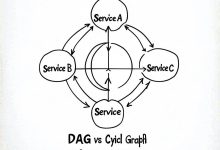
本文是《程序员数学扫盲课》系列文章 ← 上一篇:程序员数学03:集合论 – Redis与SQL | → 下一篇:程序员数学05:概率论 – 系统可用性 TL;DR 为什么微服务会出现循环依赖?为什么CI/CD流水线要...
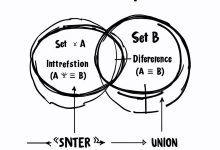
本文是《程序员数学扫盲课》系列文章 ← 上一篇:程序员数学02:对数Log – 数据库索引 | → 下一篇:程序员数学04:图论 – 微服务依赖管理 TL;DR 为什么Redis的SINTER能瞬间找出共同好友?为什...
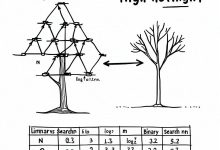
本文是《程序员数学扫盲课》系列文章 ← 上一篇:程序员数学01:破冰篇 – 数学符号就是代码 | → 下一篇:程序员数学03:集合论 – Redis与SQL TL;DR 为什么MySQL能在1000万条数据里瞬间找到...
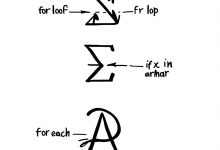
本文是《程序员数学扫盲课》系列文章 → 下一篇:程序员数学02:对数Log – 数据库索引 TL;DR 写了10年代码,看到数学符号就头疼?其实那些吓人的希腊字母,翻译成代码你早就会了。这篇文章把最常见的6个数学符号直接对应到G...
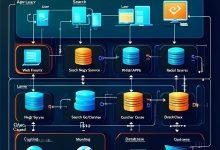
第06章:生产环境部署:从原型到产品 监控系统、缓存策略、容量规划确保搜索系统稳定运行 📝 TL;DR (核心要点速览) – 部署架构:主从复制 + 读写分离 + 负载均衡 – 性能调优:数据库参数优化 + 查询缓存...
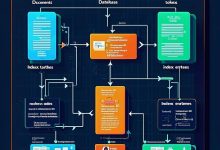
第05章:搜索查询优化:从SQL到结果排序 复杂SQL查询实现毫秒级搜索响应,排序算法决定用户体验 📝 TL;DR (核心要点速览) – 查询核心:复杂JOIN + 聚合函数实现多维度权重计算 – 性能关键:参数化查...
第04章:索引系统架构:高性能数据存储 两个核心表支撑整个搜索系统,批量操作决定性能 📝 TL;DR (核心要点速览) – 核心设计:index_tokens + index_entries = 完整反向索引 – 性...

第03章:权重系统设计:相关性评分的科学 三层权重架构实现精确相关性控制,这是搜索质量的核心 📝 TL;DR (核心要点速览) – 核心公式:$finalWeight = $fieldWeight × $tokenizerWei...

第02章:搜索引擎核心原理:Tokenization的艺术 搜索质量取决于分词策略,这是搜索引擎的DNA 📝 TL;DR (核心要点速览) – 核心概念:Tokenization是将文本转换为可搜索单元的艺术 – 四...
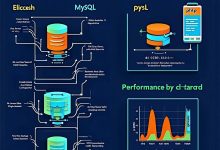
第01章:为什么需要自建搜索引擎 当所有人都说”用Elasticsearch”时,我们选择回到第一性原理 📝 TL;DR (核心要点速览) – 核心问题:外部搜索服务复杂、昂贵、依赖性强 – ...
从零构建可用搜索引擎:数据库驱动的搜索系统实战 当所有人都说”用Elasticsearch”时,我们选择回到第一性原理 📝 TL;DR (系列总览) – 核心问题:为什么现代搜索系统越来越复杂? R...
B树深度教学系列(五):替代方案与未来趋势 从B树到AI索引:数据结构选择的演进与未来 📝 TL;DR (核心要点速览) 🎯 本篇核心: B树不是唯一选择,场景决定了最优数据结构 💡 关键发现: – B树适合:通用OLTP、中等...

B树深度教学系列(四):生产环境实现 – 从理论到工程实践 数据库工程师的实战指南:B树在真实系统中的工程挑战 📝 TL;DR (核心要点速览) 🎯 本篇核心: 生产环境中的B树实现远比教科书复杂 💡 关键发现: –...
 Toy
Toy





 程序员数学扫盲课
程序员数学扫盲课 AI周刊:大模型、智能体与产业动态追踪
AI周刊:大模型、智能体与产业动态追踪 Claude Code 全体系指南:AI 编程智能体实战
Claude Code 全体系指南:AI 编程智能体实战 Karpathy神经网络零基础课程
Karpathy神经网络零基础课程
最新评论
开源的AI对话监控面板很实用,正好团队在找这类工具。准备试用一下。
折叠屏市场确实在升温,不过售罄也可能是备货策略。期待看到实际销量数据。
从磁盘I/O角度解释B树的设计动机,这个切入点很好。终于理解为什么数据库不用二叉树了。
IT术语转换确实是个痛点,之前用搜狗总是把技术词汇转成奇怪的词。智谱这个方向值得期待。
这个工具结合LLM和搜索API的思路很有意思,正好解决了我在做知识管理时遇到的问题。请问有没有部署文档?
这个漏洞确实严重,我们团队上周刚遇到类似问题。建议补充一下如何检测现有项目是否受影响的方法。
从简单规则涌现复杂性这个思路很有意思,让我想起元胞自动机。不过数字物理学在学术界争议还挺大的。
我也遇到了指令跟随变差的问题,特别是多轮对话时容易跑偏。不知道是模型退化还是负载优化导致的。