Artificial Analysis 更新了最新的 AI 模型能力榜单。
这次更新出现了 GPT-5.2、Claude Opus 4.5、Gemini 3 Pro 等尚未正式公测的”未来旗舰”模型。模型能力的代际跨越即将到来。
综合智力:硅谷御三家的统治
在 Intelligence Index(综合智力指数)中,硅谷”御三家”确立了绝对优势。
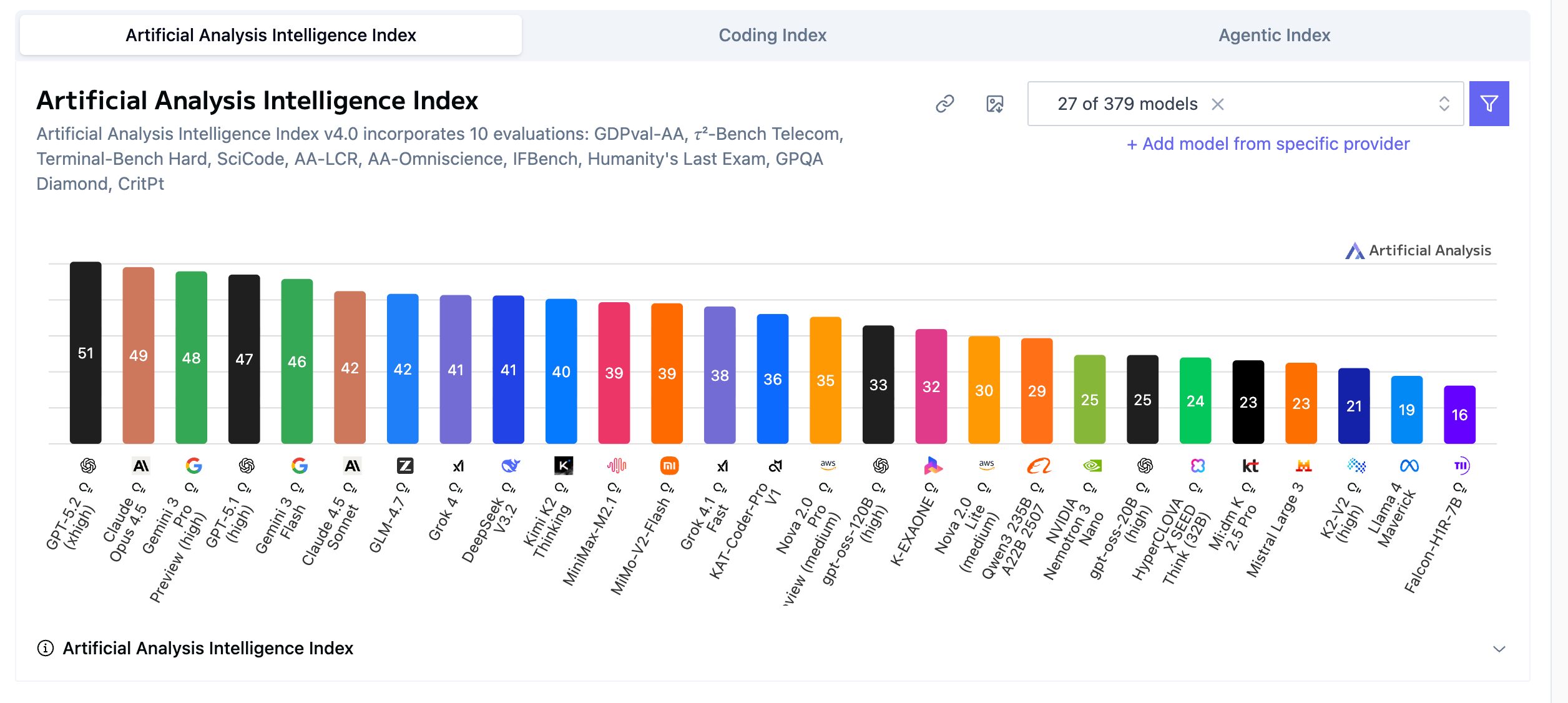
GPT-5.2 领跑:以 51分 断层领先,稳坐头把交椅。
第二梯队:Claude Opus 4.5 以 49分 紧随其后,Gemini 3 Pro Preview 拿下 48分。
国产模型位置:DeepSeek V3.2 和 GLM-4.7 站在 41分 档,位列全球第二梯队前列。
纯智力的比拼已经进入”5.0时代”。推理、常识、知识储备这些基础能力,头部效应愈发明显。
智能体能力:国产模型杀入前三
Agentic Index(智能体指数)代表的是解决实际问题的能力。
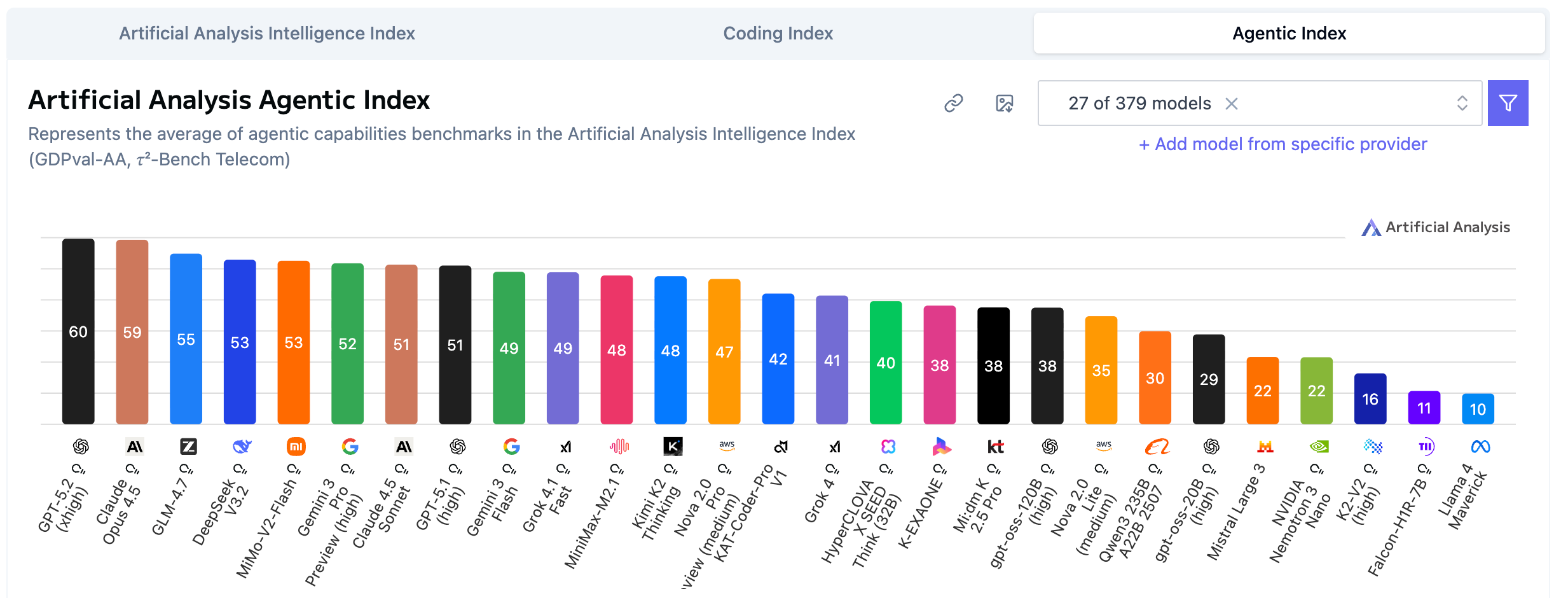
GLM-4.7 第三:拿下 55分,仅次于 GPT-5.2 和 Claude Opus 4.5。
DeepSeek 和小米:DeepSeek V3.2 和 MiMo-V2-Flash 同积 53分,并列第四。
对比优势:国产模型在 Agent 领域与 Gemini 3 系列(52分)相比略占上风。
工具调用、复杂任务规划和执行,国产模型已经具备了与世界顶尖模型掰手腕的能力。相比于刷通识题库,让 AI 真正”干活”的能力,国内模型走在了前面。
代码能力:OpenAI 继续领跑
Coding Index(代码能力指数)的格局回归传统分布。
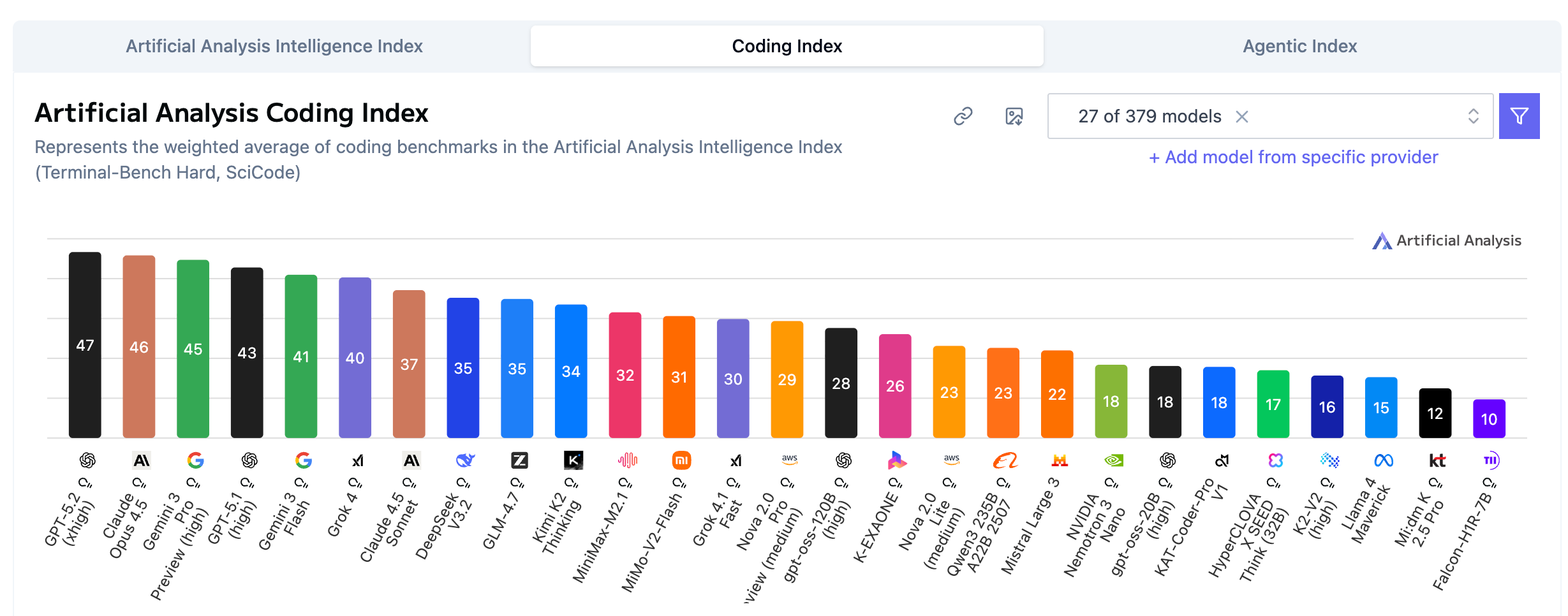
GPT-5.2 第一:47分 领跑,代码逻辑和生成质量依然是行业天花板。
Claude 第二:Claude Opus 4.5 拿下 46分,一分之差紧咬不放。
开源差距:开源模型(如 Llama 4 Maverick)与顶尖闭源模型的分数差距明显(15分 vs 47分)。代码生成需要极强的逻辑一致性和超长上下文把控,这是巨头们的护城河。
2025-2026 年的格局
版本号大跃进
GPT-5、Claude 4.5/Opus、Gemini 3、Llama 4……这些名字意味着模型能力的又一次指数级跃升。
“偏科”成为常态
没有模型能全方位无死角碾压。GPT-5.2 综合最强,GLM-4.7 在 Agent 任务上性价比高,Claude 在 Coding 上依然优雅。
国产 AI 的务实路线
在 Agentic Index 上的表现,证明了国产大模型在”实用性”上的进步。不盲目追求参数量,而是追求解决复杂任务的成功率。
数据来源:Artificial Analysis Index v4.0
注:部分模型可能为预测型号或预览版本,实际性能以官方发布为准。






 AI周刊:大模型、智能体与产业动态追踪
AI周刊:大模型、智能体与产业动态追踪 程序员数学扫盲课
程序员数学扫盲课 冲浪推荐:AI工具与技术精选导航
冲浪推荐:AI工具与技术精选导航 Claude Code 全体系指南:AI 编程智能体实战
Claude Code 全体系指南:AI 编程智能体实战
最新评论
Flash版本的响应速度确实提升明显,但我在使用中发现对中文的理解偶尔会出现一些奇怪的错误,不知道是不是普遍现象?
遇到过类似问题,最后发现是网络环境的问题。建议加一个超时重试机制的示例代码。
谢谢分享,我是通过ChatGPT的索引找到这里来的。
十年打磨一个游戏确实罕见,这种专注度在快节奏的游戏行业很难得。从Braid到The Witness,每作都是精品。
快捷键冲突是个很实际的问题,我自己也被这个问题困扰过。最后通过自定义快捷键组合解决了。
会议摘要这个功能很实用,特别是对经常需要参加长会议的人。不过三次免费使用确实有点少了。
硕士背景转AI基础设施,这个路径其实挺常见的。建议多关注底层系统知识,而不只是模型应用层面。
配置虽然简单,但建议补充一下认证和加密的注意事项,避免被中间人攻击。