
大模型面试100问08:开源生态篇
TL;DR 开源大模型已经追上闭源——LLaMA 3.1 405B在多项任务上接近GPT-4,Qwen 2.5在中文理解上超越GPT-4o。选模型不是看参数大小,而是看任务适配:LLaMA生态最丰富、Mistral推理最快、Qwen中文最强...

TL;DR 开源大模型已经追上闭源——LLaMA 3.1 405B在多项任务上接近GPT-4,Qwen 2.5在中文理解上超越GPT-4o。选模型不是看参数大小,而是看任务适配:LLaMA生态最丰富、Mistral推理最快、Qwen中文最强...
TL;DR 稠密模型的参数规模竞赛已经到头,MoE用稀疏激活让470亿参数的模型跑出130亿的速度;多模态让LLM能看图说话,GPT-4V的视觉编码器是关键;Diffusion模型让AI能画画,DDPM和DDIM是两条技术路线。本文从6个高...
TL;DR 评估和安全是LLM落地的两大关键——不能衡量就无法改进,不能保护就不敢上线。BLEU/ROUGE适合机器翻译但不适合开放生成,困惑度只能评估语言建模能力;幻觉检测用语义熵,偏见测量用CrowS-Pairs;红队测试模拟攻击,差分...
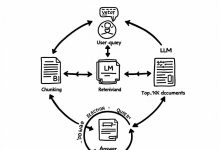
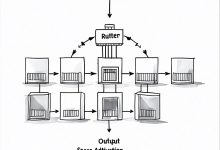
TL;DR LLM的知识有截止日期,RAG让它能查最新资料;LLM只会聊天,Agent让它能干活。RAG的核心是检索+生成,文档分块策略直接影响效果;Agent的核心是感知+规划+记忆+工具,ReAct架构让它能像人一样思考和行动。本文从8...
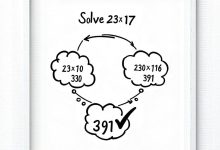
TL;DR Prompt工程是让LLM听懂人话的艺术——同样的问题,换个问法效果天差地别。”让我们一步步思考”这句话为什么能让GPT-4准确率从17%提升到79%?Tree of Thoughts如何让模型像下棋一样...
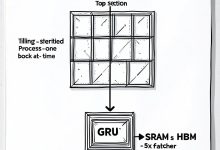
TL;DR 推理才是大模型的真正战场——训练一次,推理百万次。标准Attention的内存带宽成为瓶颈,Flash Attention通过Tiling技术让速度提升5倍;KV Cache让解码快10倍,但长上下文会吃掉几十GB显存;vLLM...
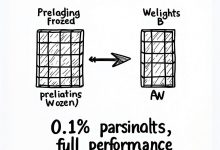
TL;DR 全参数微调一个7B模型要14GB显存,65B模型要130GB——普通人根本玩不起。但LoRA只需要0.1%的参数,QLoRA更狠,单张24GB显卡就能训65B模型。本文从10个高频面试题入手,带你搞懂大模型训练的核心技术:LoR...
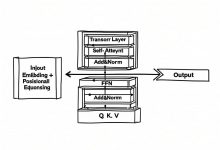
TL;DR 面试官问你Transformer原理,你能答到什么深度?本文从12个高频面试题入手,带你搞懂大模型的底层架构——不是背概念,是真正理解为什么GPT用单向注意力、LLaMA为什么选RoPE、多头注意力到底在干什么。读完这篇,你能用...

大模型面试100问:从基础到实战的完整指南 为什么需要这个系列? 大模型面试不是背八股文——面试官要的是系统性理解和实战经验。市面上的面试题要么太碎片化(100个孤立问题),要么太理论化(只讲公式不讲应用)。 这个系列不一样: ✅ 系统化:...
 Toy
Toy





 程序员数学扫盲课
程序员数学扫盲课 AI周刊:大模型、智能体与产业动态追踪
AI周刊:大模型、智能体与产业动态追踪 Claude Code 全体系指南:AI 编程智能体实战
Claude Code 全体系指南:AI 编程智能体实战 Karpathy神经网络零基础课程
Karpathy神经网络零基础课程
最新评论
开源的AI对话监控面板很实用,正好团队在找这类工具。准备试用一下。
折叠屏市场确实在升温,不过售罄也可能是备货策略。期待看到实际销量数据。
从磁盘I/O角度解释B树的设计动机,这个切入点很好。终于理解为什么数据库不用二叉树了。
IT术语转换确实是个痛点,之前用搜狗总是把技术词汇转成奇怪的词。智谱这个方向值得期待。
这个工具结合LLM和搜索API的思路很有意思,正好解决了我在做知识管理时遇到的问题。请问有没有部署文档?
这个漏洞确实严重,我们团队上周刚遇到类似问题。建议补充一下如何检测现有项目是否受影响的方法。
从简单规则涌现复杂性这个思路很有意思,让我想起元胞自动机。不过数字物理学在学术界争议还挺大的。
我也遇到了指令跟随变差的问题,特别是多轮对话时容易跑偏。不知道是模型退化还是负载优化导致的。