调试 AI Agent:为什么"它为什么不工作"是最难的问题
跑了一个月 AI 助手,我发现最难的不是让它变聪明,而是找出它为什么不聪明。 人类调试: 看日志,找错误,修 bug。 AI 调试: 它说”我理解了”,但输出完全不是那回事。 问题在哪? 黑盒问题 你不知道它R...



跑了一个月 AI 助手,我发现最难的不是让它变聪明,而是找出它为什么不聪明。 人类调试: 看日志,找错误,修 bug。 AI 调试: 它说”我理解了”,但输出完全不是那回事。 问题在哪? 黑盒问题 你不知道它R...

刷到一条 8 分钟左右的视频,核心信息其实很集中: Anti-Gravity(Google 的 agent-first IDE)把“写代码”从补全升级成 计划→执行→测试→交付 的闭环 Kimi 2.5(Moonshot AI 的多模态模型...

官方 Claude Code 又涨价又 KYC,封号了还得自己重新折腾环境?ReClaude 拼车了解一下——200 / 400 / 800 / 1600 四档随便挑,账号、风控、切换全平台托管,触发风控自动换号不计次。本地 daemon 三行命令装好,Claude Code / Codex / Cursor / MCP 原来怎么用还怎么用。我自己跑 4 人车那档,性价比最平衡。
本文作者测评了近期热门的 UI 设计工具 pencil.dev。该工具专为缺乏 UI/UX 经验的开发者打造,支持自动连接 MCP 并提供精调模板。通过实际构建时间线项目,作者对比了传统工作流,展示了从 Gemini 讨论需求、Claude...
TL;DR 价格: 70元/年 (2C2G配置) 位置: 美国洛杉矶 核心优势: 47系列IP国内直连延迟<1ms,Claude/Gemini/ChatGPT/Sora全解锁 适用场景: 大模型API中转、轻量级海外服务、媒体解锁测试...
受限于公司保密机制,某开发者在本地无法使用闭源模型,仅能测试内部部署的 GLM-4.7 和 MiniMax-M2.1 等开源模型,以及隔离在堡垒机上的 GitHub Copilot。在 C++ 项目实测中发现,无论是 Claude Code...
谷歌 Chrome 浏览器近日被曝出正在测试名为“Let Chrome browse for you”的 AI 功能,旨在利用 Agent 模式替用户自动浏览网页。目前有用户反馈该选项处于灰色禁用状态,疑似需要特定权限或处于灰度测试阶段。用...

摘要:当全网都在跪求 Manus 邀请码,或是在 Anthropic Cowork 的 Waiting List 中苦苦等待时,GitHub 榜首的一款国人开源项目 AionUi 已经悄然交出了答卷。它不是 IDE 的插件,而是对标 Ant...
近期社区讨论显示,多位用户反馈 Claude Pro 及 5x Max 版本在使用中频繁触发 5 小时限额,而 GPT Plus 则极少出现此类限制。这种显著的差异引发了用户对两者配额机制的质疑。分析认为,这背后反映了 Anthropic ...

Artificial Analysis 最新战力榜揭示了一个被忽略的真相——OpenAI 正在失去”全能王”的宝座。 TL;DR GPT-5.2 以 51 分称霸综合智力榜,但领先优势正在收窄 国产黑马杀入:GLM-...
本文分享了开发者利用 ChatGPT 和 Gemini Pro 协助定制开发 Chromium v137 的实战经验。在长达半年的开发周期中,项目涉及修改超过 300 个代码文件,生成约 2 万行补丁代码。作者指出,AI 在处理复杂代码逻辑...
本文分享了作者利用LLM(DeepSeek、Gemini、Kimi)构建日语歌词学习自动化流水线的经历。通过对比不同模型在上下文窗口、推理能力和指令遵循方面的表现,作者最终利用Gemini 2.5实现了从假名转写、生词解释到Anki卡片生成...
一位开发者在试用 GPT 代码功能时发现,其生成的注释风格过于口语化,与 Claude Sonnet 4.5 的严谨风格形成对比。此外,GPT 倾向于默认添加注释,而 Claude 重写时可能省略。更值得注意的是,GPT 擅自将数据精度从 ...

2026 年 1 月 9 日,Google Antigravity 的 Pro 用户集体遭遇了一次”时间膨胀”。 原本每 5 小时刷新一次的 Claude 和 GPT 额度,突然变成了 2-4 天,甚至有人看到重置时...
一位资深Java/Python开发者分享了AI编程工具的亲身体验。该用户长期使用付费版Claude Code,近期试用GPT Plus、Gemini Pro、Codex和Gemini CLI后,发现后两者在性能和使用体验上均不及Claude...
作者通过DeepResearch平台,使用精心设计的提示词系统性收集Claude Skills开源资源,并在Linux社区分享测试过程。对比Grok(专家模式)、Gemini(Pro)和ChatGPT(5.2 Pro)的执行效果,发现Gro...
本文探讨了Gemini与Claude两大AI模型的写作风格差异。Gemini偏好堆砌形容词,而Claude保持文风简洁自然。作者在学术写作中倾向于Claude,认为其更实用,除非对Gemini设置强约束。这一比较为用户选择AI写作工具提供了...

系列导航:返回 CKA-Agent 系列总览 | 上一篇:自适应树搜索的智能博弈 | 下一篇:从攻击到防御的演化之路 96.9% 对 Claude-Haiku-4.5。 95.1% 对 Gemini-3.0-Pro。 93.2% 对 GPT...

TL;DR 开源大模型已经追上闭源——LLaMA 3.1 405B在多项任务上接近GPT-4,Qwen 2.5在中文理解上超越GPT-4o。选模型不是看参数大小,而是看任务适配:LLaMA生态最丰富、Mistral推理最快、Qwen中文最强...
TL;DR 稠密模型的参数规模竞赛已经到头,MoE用稀疏激活让470亿参数的模型跑出130亿的速度;多模态让LLM能看图说话,GPT-4V的视觉编码器是关键;Diffusion模型让AI能画画,DDPM和DDIM是两条技术路线。本文从6个高...
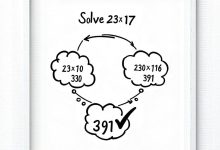
TL;DR Prompt工程是让LLM听懂人话的艺术——同样的问题,换个问法效果天差地别。”让我们一步步思考”这句话为什么能让GPT-4准确率从17%提升到79%?Tree of Thoughts如何让模型像下棋一样...
 AtuiBot
AtuiBot Toy
Toy






 AI周刊:大模型、智能体与产业动态追踪
AI周刊:大模型、智能体与产业动态追踪