从 Hermes Agent 漏洞看 AI 安全:防御体系将从“防火墙”转向“数字疫苗”?
Hermes Agent 近日被披露存在首个远程代码执行(RCE)漏洞,这一技术细节引发了行业对 AI 时代安全模式的深刻思考。传统的“防火墙”式被动防御在面对高度智能化的 AI Agent 时显得力不从心,未来的网络安全行业或将发生根本性...


Hermes Agent 近日被披露存在首个远程代码执行(RCE)漏洞,这一技术细节引发了行业对 AI 时代安全模式的深刻思考。传统的“防火墙”式被动防御在面对高度智能化的 AI Agent 时显得力不从心,未来的网络安全行业或将发生根本性...
随着用户搜索习惯向 AI 转移,Dageno AI 正式推出了专为大模型时代设计的 GEO(生成式引擎优化)平台。该平台通过大规模并发 Agent 技术,直接在 ChatGPT、Gemini 等 7 大主流 LLM 前端采集数据,而非依赖不...

ECS / OSS / CDN / 云数据库一站采购,常用云资源集中选配;新用户与续费均有专场优惠,适合个人开发者与小团队长期使用。
引言(The Hook):你是不是还在为每天手动“调教”各种 AI 助手而心力交瘁?我们曾经以为给大模型套个复杂的网关调度就是 Agent,那是最初级的思维。而在过去 30 天,我停掉了手里 80% 的常规任务流,将它们全部迁移到了 Her...
多信源聚合显示,OpenAI将在未来24至48小时内密集发布重磅更新。全新图像模型GPT-Image-2几乎确定于今晚上线,备受期待的GPT-5.5模型也预计于周四发布。与此同时,ChatGPT被曝正在测试代号为“Hermes”的全新Age...
谷歌内部已秘密组建由顶级工程师构成的“突击队”,旨在提升AI代码生成能力以反击竞争对手Anthropic。联合创始人谢尔盖·布林亲自挂帅,目标直指“AI起飞”,即利用谷歌庞大的私有代码库训练模型,实现AI的自我改进。为推动这一激进转型,谷歌...
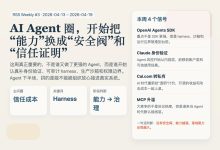
这一周最值得记住的,不是又多了几个 Agent SDK,也不是哪家模型又把能力榜单往前推了一格。 真正的变化是,AI Agent 这条线开始从“能不能做更多事”,转向“谁敢把它放进真实系统里”。安全、身份校验、可审计 harness、生产级沙箱、策略透明度,这些过去常被当成配套件的东西,这一周开始越来越像主产品。 换句
Uber在2026年面临AI转型的“甜蜜烦恼”。尽管投入了34亿美元研发资金,但由于工程师对Anthropic Claude等AI编程工具的使用激增,公司AI预算已提前告急。目前,AI已编写了Uber 11%的后端代码,虽然CTO展望了由A...

最近一年做 Agent 的人,几乎都会在同一个地方反复撞墙: 模型越来越强,工具链越来越长,但对话一断、会话一换,系统就像“失忆”一样,重新变回一个陌生助手。 很多团队把这个问题当成“再接个向量库”就能解决的工程细节。看完这期视频后,我反而更确定: 真正的分水岭,不在“有没有记忆”,而在“你把记忆当成什么”。 是把它当
检索增强生成(RAG)虽是当前构建 AI 知识库的主流技术,但近期社区中关于其实现复杂度高、回答效果不稳定的质疑声不断。随着大模型上下文窗口的显著增加以及智能体技术的成熟,开发者开始重新思考知识库的最优架构。本文讨论了在 RAG 之外,利用...
随着AI模型从单一对话向智能体形态演进,其背后的算力与推理成本问题日益凸显。本文引用了对Claude 4.7分词器成本等相关讨论,深入探讨了在2025年,AI智能体的经济成本是否正随着智能水平的提升而呈指数级增长。文章分析了在追求更高级自主...

 Toy
Toy





 Codex CLI 深度
Codex CLI 深度 AI 模型横评
AI 模型横评 AI Agent 框架
AI Agent 框架 Claude Code 订阅生存指南
Claude Code 订阅生存指南