大模型周刊 第14期 (2026年1月4日-1月10日)
本周概览 本周AI领域继续高频迭代。ChatGPT进军健康应用但引发隐私争议,Cursor估值飙升至293亿美元并强化自治功能,Claude Code优化工具链,Gemini深度整合Gmail带来显著体验提升。 数据来源于科技媒体报道和X平...
本周概览 本周AI领域继续高频迭代。ChatGPT进军健康应用但引发隐私争议,Cursor估值飙升至293亿美元并强化自治功能,Claude Code优化工具链,Gemini深度整合Gmail带来显著体验提升。 数据来源于科技媒体报道和X平...

2026 年 1 月 9 日,Google Antigravity 的 Pro 用户集体遭遇了一次”时间膨胀”。 原本每 5 小时刷新一次的 Claude 和 GPT 额度,突然变成了 2-4 天,甚至有人看到重置时...
🚀 速来拼好模,智谱 GLM Coding 超值订阅,邀你一起薅羊毛!Claude Code、Cline 等 20+ 大编程工具无缝支持,”码力”全开,越拼越爽!立即开拼,享限时惊喜价! 链接 智谱最近上市了,搞了个...
在 Claude Code 2.1.0 的更新日志里,context: fork 可能只是不起眼的一行,但对于追求极致效率的硬核开发者来说,这才是真正的王炸。 今天,我们通过一个实战案例——“全自动代码坏味道审计”,带你深度拆解这个“平行宇...
Claude Code 2.1.0 深度实测:从 AI 助手到“多智能体原生”操作系统的跨越 如果说 AI 编程的 1.0 时代是对话框里的 Copy-Paste,2.0 时代是 IDE 里的智能补全,那么 Claude Code 2.1....

NVIDIA NIM 是什么 NVIDIA NIM(NVIDIA Inference Microservices)是英伟达推出的推理服务平台,提供多家厂商的 AI 模型 API。重点是:部分模型免费调用,包括智谱 GLM-4.7 和 Min...

系列导航:返回 CKA-Agent 系列总览 | 上一篇:主流模型防线崩溃实录 当 96% 的攻击都能成功时,防御者该如何应对? CKA-Agent 不是第一个越狱工具,也不会是最后一个。但它的出现标志着 AI 安全进入了一个新纪元:单点防...

系列导航:返回 CKA-Agent 系列总览 | 上一篇:自适应树搜索的智能博弈 | 下一篇:从攻击到防御的演化之路 96.9% 对 Claude-Haiku-4.5。 95.1% 对 Gemini-3.0-Pro。 93.2% 对 GPT...

系列导航:返回 CKA-Agent 系列总览 | 上一篇:无害提示编织的攻击艺术 | 下一篇:主流模型防线崩溃实录 无害提示编织告诉我们”问什么”,但真正的挑战是”怎么问”。 当第一个子问题被...

系列导航:返回 CKA-Agent 系列总览 | 下一篇:自适应树搜索的智能博弈 当 AI 的安全防线能够识别 99% 的恶意提示时,攻击者找到了一条绕过的新路径:不再直接对抗,而是将恶意目标拆解为无数个无害碎片。 这就是”无害...

TL;DR 哥,新年快乐!这周咱们不仅跨了个年,还跨过了一个 AI 时代的门槛。 本周(2025.12.28 – 2026.01.04)虽然有假期buff,但几大巨头都没闲着。最大的体感是:AI 正在从“手里的铲子”进化成“带项...
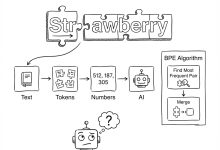
本文是《Karpathy神经网络零基础课程》系列文章 ← 上一篇:Karpathy神经网络07:GPT – 从零实现ChatGPT | → 下一篇:无 这是一个关于大语言模型(LLM)幕后功臣——Tokenizer(分词器)的硬...
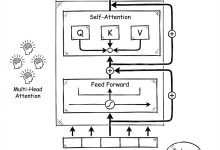
本文是《Karpathy神经网络零基础课程》系列文章 ← 上一篇:Karpathy神经网络06:WaveNet – 神经网络大升级 | → 下一篇:Karpathy神经网络08:Tokenizer – 为什么AI不识...
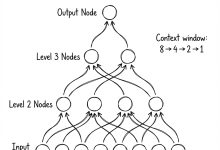
本文是《Karpathy神经网络零基础课程》系列文章 ← 上一篇:Karpathy神经网络05:反向传播 – 徒手写梯度 | → 下一篇:Karpathy神经网络07:GPT – 从零实现ChatGPT 这是Andr...
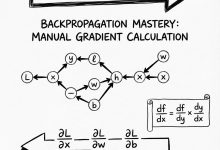
本文是《Karpathy神经网络零基础课程》系列文章 ← 上一篇:Karpathy神经网络04:BatchNorm – 解决训练崩盘 | → 下一篇:Karpathy神经网络06:WaveNet – 神经网络大升级 ...
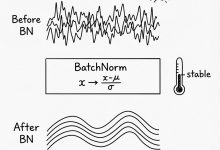
本文是《Karpathy神经网络零基础课程》系列文章 ← 上一篇:Karpathy神经网络03:MLP – 多层感知机 | → 下一篇:Karpathy神经网络05:反向传播 – 徒手写梯度 这是一篇为您准备的关于 ...
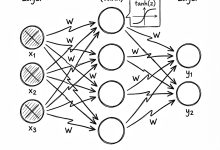
本文是《Karpathy神经网络零基础课程》系列文章 ← 上一篇:Karpathy神经网络02:Makemore – 语言模型入门 | → 下一篇:Karpathy神经网络04:BatchNorm – 解决训练崩盘 ...
本文是《Karpathy神经网络零基础课程》系列文章 ← 上一篇:Karpathy神经网络01:Micrograd – 手撸一个AI大脑 | → 下一篇:Karpathy神经网络03:MLP – 多层感知机 这是一篇...
本文是《Karpathy神经网络零基础课程》系列文章 ← 上一篇:无 | → 下一篇:Karpathy神经网络02:Makemore – 语言模型入门 这不仅是一个视频总结,更是一堂为你量身定制的 AI 原理启蒙课。 视频的作者...

TL;DR 开源大模型已经追上闭源——LLaMA 3.1 405B在多项任务上接近GPT-4,Qwen 2.5在中文理解上超越GPT-4o。选模型不是看参数大小,而是看任务适配:LLaMA生态最丰富、Mistral推理最快、Qwen中文最强...
 Toy
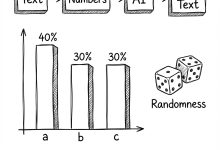
Toy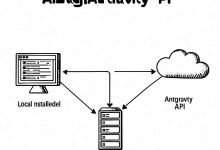
 AI周刊:大模型、智能体与产业动态追踪
AI周刊:大模型、智能体与产业动态追踪 程序员数学扫盲课
程序员数学扫盲课 冲浪推荐:AI工具与技术精选导航
冲浪推荐:AI工具与技术精选导航 Claude Code 全体系指南:AI 编程智能体实战
Claude Code 全体系指南:AI 编程智能体实战
最新评论
开源的AI对话监控面板很实用,正好团队在找这类工具。准备试用一下。
折叠屏市场确实在升温,不过售罄也可能是备货策略。期待看到实际销量数据。
从磁盘I/O角度解释B树的设计动机,这个切入点很好。终于理解为什么数据库不用二叉树了。
IT术语转换确实是个痛点,之前用搜狗总是把技术词汇转成奇怪的词。智谱这个方向值得期待。
这个工具结合LLM和搜索API的思路很有意思,正好解决了我在做知识管理时遇到的问题。请问有没有部署文档?
这个漏洞确实严重,我们团队上周刚遇到类似问题。建议补充一下如何检测现有项目是否受影响的方法。
从简单规则涌现复杂性这个思路很有意思,让我想起元胞自动机。不过数字物理学在学术界争议还挺大的。
我也遇到了指令跟随变差的问题,特别是多轮对话时容易跑偏。不知道是模型退化还是负载优化导致的。