YouTube播放列表批量下载脚本
一个简单而强大的Bash脚本,利用yt-dlp工具实现YouTube播放列表的批量下载和智能组织。脚本按频道名称创建独立目录,支持智能同步以跳过已下载文件,采用清洁命名格式(播放标题/视频标题.mp4),并能批量处理多个播放列表。用户需安装...


一个简单而强大的Bash脚本,利用yt-dlp工具实现YouTube播放列表的批量下载和智能组织。脚本按频道名称创建独立目录,支持智能同步以跳过已下载文件,采用清洁命名格式(播放标题/视频标题.mp4),并能批量处理多个播放列表。用户需安装...
一位开发者分享使用Claude Code的惊人成本,月耗超过4000美元,引发社区热议。为解决工具使用不便问题,作者开源了IDEA版Claude Code GUI插件v0.2,提供可视化操作界面,支持Codex等CLI工具集成。项目已在Gi...

官方 Claude Code 又涨价又 KYC,封号了还得自己重新折腾环境?ReClaude 拼车了解一下——200 / 400 / 800 / 1600 四档随便挑,账号、风控、切换全平台托管,触发风控自动换号不计次。本地 daemon 三行命令装好,Claude Code / Codex / Cursor / MCP 原来怎么用还怎么用。我自己跑 4 人车那档,性价比最平衡。
GitHub开源项目BypassAIGC新增Word排版实验性功能,支持中英文论文润色和AIGC降重。项目已获500多stars,显示降重需求旺盛。默认启用思考模式提升文本质量,朱雀AI检测稳定通过。建议配合CLIProxyAPI使用,享受...
一位拥有后端基础和实习经验的技术人员,因对后端发展局限和薪资差距的担忧,计划转向大模型开发领域。他寻求学习路径和项目实践建议,以提升春招竞争力。分享了对AI职业转型的思考,讨论了大模型开发的技能需求和行业趋势。 原文链接:Linux.do
Claude Code在处理请求时,每次都会携带大量上下文信息,导致200K的Token限制很快耗尽,影响使用效率。用户寻求优化手段,除了利用subAgent切分任务外,还探讨其他减少Token浪费的方法。同时,请教Cursor和Winds...
用户刚体验Gemini 3模型,优化了前端界面,并分享了与Claude Code的对比结果。用户怀疑是自己使用方式不当,寻求社区帮助以获取最佳实践建议。帖子包含图片对比,为其他用户提供参考价值。这反映了AI工具在实际应用中的优化需求,强调了...
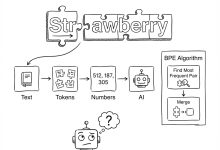
本文是《Karpathy神经网络零基础课程》系列文章 ← 上一篇:Karpathy神经网络07:GPT – 从零实现ChatGPT | → 下一篇:无 这是一个关于大语言模型(LLM)幕后功臣——Tokenizer(分词器)的硬...
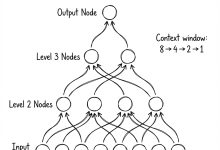
本文是《Karpathy神经网络零基础课程》系列文章 ← 上一篇:Karpathy神经网络06:WaveNet – 神经网络大升级 | → 下一篇:Karpathy神经网络08:Tokenizer – 为什么AI不识...
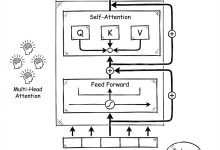
本文是《Karpathy神经网络零基础课程》系列文章 ← 上一篇:Karpathy神经网络05:反向传播 – 徒手写梯度 | → 下一篇:Karpathy神经网络07:GPT – 从零实现ChatGPT 这是Andr...
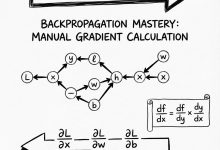
本文是《Karpathy神经网络零基础课程》系列文章 ← 上一篇:Karpathy神经网络04:BatchNorm – 解决训练崩盘 | → 下一篇:Karpathy神经网络06:WaveNet – 神经网络大升级 ...
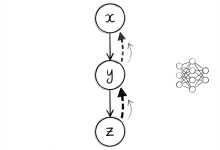
本文是《Karpathy神经网络零基础课程》系列文章 ← 上一篇:Karpathy神经网络03:MLP – 多层感知机 | → 下一篇:Karpathy神经网络05:反向传播 – 徒手写梯度 这是一篇为您准备的关于 ...
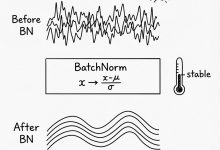
本文是《Karpathy神经网络零基础课程》系列文章 ← 上一篇:Karpathy神经网络02:Makemore – 语言模型入门 | → 下一篇:Karpathy神经网络04:BatchNorm – 解决训练崩盘 ...
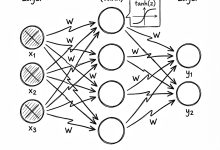
本文是《Karpathy神经网络零基础课程》系列文章 ← 上一篇:Karpathy神经网络01:Micrograd – 手撸一个AI大脑 | → 下一篇:Karpathy神经网络03:MLP – 多层感知机 这是一篇...
本文是《Karpathy神经网络零基础课程》系列文章 ← 上一篇:无 | → 下一篇:Karpathy神经网络02:Makemore – 语言模型入门 这不仅是一个视频总结,更是一堂为你量身定制的 AI 原理启蒙课。 视频的作者...
开发者分享在VSCode的Windows WSL2环境下配置Antigravity插件的失败经历。经过多次尝试,导入后插件无法加载,用户怀疑该插件目前仅适用于Linux系统。帖子引发同行讨论,寻求成功配置经验和解决方案。这反映了跨平台开发工...
Nightshade是芝加哥大学开发的一种创新工具,旨在通过污染图像数据来保护知识产权。它通过在图像中添加人眼不可见的扰动,使这些图像在用于AI模型训练时引入错误,从而阻止模型学习正确内容。该工具有效应对了AI训练中的数据滥用问题,但存在局...
知名技术博主Jeff Geerling宣布将其个人博客从Drupal迁移到Hugo静态站点生成器。自2009年以来,博客一直运行在Drupal上,但作者因维护复杂、升级繁琐而选择迁移。Hugo提供了更简单的Markdown工作流,显著提升了...
本文聚焦于Linux社区中,针对使用kiro和antigravity工具代理Claude AI模型给用户(cc)的技术探讨。多种解决方案被提出,用户核心诉求是寻求最稳定可靠的部署方法。讨论涵盖网络优化、模型性能调校和稳定性保障,为AI模型在...

TL;DR 开源大模型已经追上闭源——LLaMA 3.1 405B在多项任务上接近GPT-4,Qwen 2.5在中文理解上超越GPT-4o。选模型不是看参数大小,而是看任务适配:LLaMA生态最丰富、Mistral推理最快、Qwen中文最强...
TL;DR 稠密模型的参数规模竞赛已经到头,MoE用稀疏激活让470亿参数的模型跑出130亿的速度;多模态让LLM能看图说话,GPT-4V的视觉编码器是关键;Diffusion模型让AI能画画,DDPM和DDIM是两条技术路线。本文从6个高...

 Toy
Toy



 AI周刊:大模型、智能体与产业动态追踪
AI周刊:大模型、智能体与产业动态追踪