
英伟达NIM平台:免费调用GLM-4.7与MiniMax M2.1指南
NVIDIA NIM 是什么 NVIDIA NIM(NVIDIA Inference Microservices)是英伟达推出的推理服务平台,提供多家厂商的 AI 模型 API。重点是:部分模型免费调用,包括智谱 GLM-4.7 和 Min...
NVIDIA NIM 是什么 NVIDIA NIM(NVIDIA Inference Microservices)是英伟达推出的推理服务平台,提供多家厂商的 AI 模型 API。重点是:部分模型免费调用,包括智谱 GLM-4.7 和 Min...

系列导航:返回 CKA-Agent 系列总览 | 上一篇:主流模型防线崩溃实录 当 96% 的攻击都能成功时,防御者该如何应对? CKA-Agent 不是第一个越狱工具,也不会是最后一个。但它的出现标志着 AI 安全进入了一个新纪元:单点防...

系列导航:返回 CKA-Agent 系列总览 | 上一篇:自适应树搜索的智能博弈 | 下一篇:从攻击到防御的演化之路 96.9% 对 Claude-Haiku-4.5。 95.1% 对 Gemini-3.0-Pro。 93.2% 对 GPT...

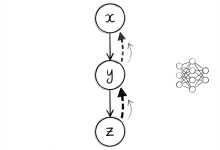
系列导航:返回 CKA-Agent 系列总览 | 上一篇:无害提示编织的攻击艺术 | 下一篇:主流模型防线崩溃实录 无害提示编织告诉我们”问什么”,但真正的挑战是”怎么问”。 当第一个子问题被...

系列导航:返回 CKA-Agent 系列总览 | 下一篇:自适应树搜索的智能博弈 当 AI 的安全防线能够识别 99% 的恶意提示时,攻击者找到了一条绕过的新路径:不再直接对抗,而是将恶意目标拆解为无数个无害碎片。 这就是”无害...

TL;DR 哥,新年快乐!这周咱们不仅跨了个年,还跨过了一个 AI 时代的门槛。 本周(2025.12.28 – 2026.01.04)虽然有假期buff,但几大巨头都没闲着。最大的体感是:AI 正在从“手里的铲子”进化成“带项...
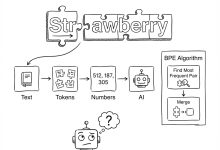
本文是《Karpathy神经网络零基础课程》系列文章 ← 上一篇:Karpathy神经网络07:GPT – 从零实现ChatGPT | → 下一篇:无 这是一个关于大语言模型(LLM)幕后功臣——Tokenizer(分词器)的硬...
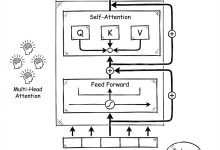
本文是《Karpathy神经网络零基础课程》系列文章 ← 上一篇:Karpathy神经网络06:WaveNet – 神经网络大升级 | → 下一篇:Karpathy神经网络08:Tokenizer – 为什么AI不识...
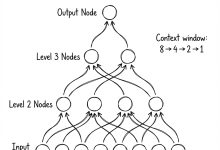
本文是《Karpathy神经网络零基础课程》系列文章 ← 上一篇:Karpathy神经网络05:反向传播 – 徒手写梯度 | → 下一篇:Karpathy神经网络07:GPT – 从零实现ChatGPT 这是Andr...
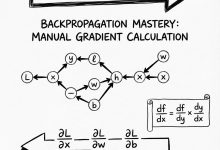
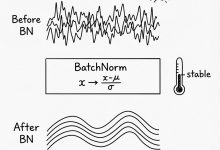
本文是《Karpathy神经网络零基础课程》系列文章 ← 上一篇:Karpathy神经网络04:BatchNorm – 解决训练崩盘 | → 下一篇:Karpathy神经网络06:WaveNet – 神经网络大升级 ...
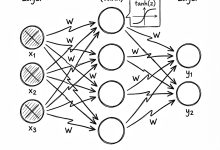
本文是《Karpathy神经网络零基础课程》系列文章 ← 上一篇:Karpathy神经网络03:MLP – 多层感知机 | → 下一篇:Karpathy神经网络05:反向传播 – 徒手写梯度 这是一篇为您准备的关于 ...
本文是《Karpathy神经网络零基础课程》系列文章 ← 上一篇:Karpathy神经网络02:Makemore – 语言模型入门 | → 下一篇:Karpathy神经网络04:BatchNorm – 解决训练崩盘 ...
本文是《Karpathy神经网络零基础课程》系列文章 ← 上一篇:Karpathy神经网络01:Micrograd – 手撸一个AI大脑 | → 下一篇:Karpathy神经网络03:MLP – 多层感知机 这是一篇...
本文是《Karpathy神经网络零基础课程》系列文章 ← 上一篇:无 | → 下一篇:Karpathy神经网络02:Makemore – 语言模型入门 这不仅是一个视频总结,更是一堂为你量身定制的 AI 原理启蒙课。 视频的作者...

TL;DR 开源大模型已经追上闭源——LLaMA 3.1 405B在多项任务上接近GPT-4,Qwen 2.5在中文理解上超越GPT-4o。选模型不是看参数大小,而是看任务适配:LLaMA生态最丰富、Mistral推理最快、Qwen中文最强...
TL;DR 稠密模型的参数规模竞赛已经到头,MoE用稀疏激活让470亿参数的模型跑出130亿的速度;多模态让LLM能看图说话,GPT-4V的视觉编码器是关键;Diffusion模型让AI能画画,DDPM和DDIM是两条技术路线。本文从6个高...
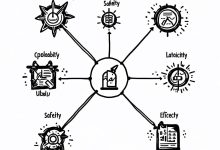
TL;DR 评估和安全是LLM落地的两大关键——不能衡量就无法改进,不能保护就不敢上线。BLEU/ROUGE适合机器翻译但不适合开放生成,困惑度只能评估语言建模能力;幻觉检测用语义熵,偏见测量用CrowS-Pairs;红队测试模拟攻击,差分...
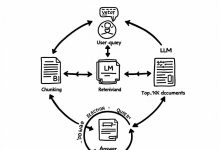
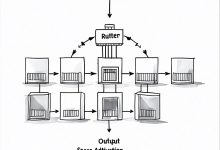
TL;DR LLM的知识有截止日期,RAG让它能查最新资料;LLM只会聊天,Agent让它能干活。RAG的核心是检索+生成,文档分块策略直接影响效果;Agent的核心是感知+规划+记忆+工具,ReAct架构让它能像人一样思考和行动。本文从8...
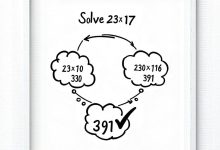
TL;DR Prompt工程是让LLM听懂人话的艺术——同样的问题,换个问法效果天差地别。”让我们一步步思考”这句话为什么能让GPT-4准确率从17%提升到79%?Tree of Thoughts如何让模型像下棋一样...
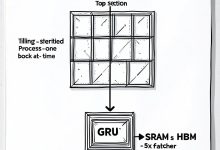
TL;DR 推理才是大模型的真正战场——训练一次,推理百万次。标准Attention的内存带宽成为瓶颈,Flash Attention通过Tiling技术让速度提升5倍;KV Cache让解码快10倍,但长上下文会吃掉几十GB显存;vLLM...
 Toy
Toy 程序员数学扫盲课
程序员数学扫盲课 AI周刊:大模型、智能体与产业动态追踪
AI周刊:大模型、智能体与产业动态追踪 Claude Code 全体系指南:AI 编程智能体实战
Claude Code 全体系指南:AI 编程智能体实战 Karpathy神经网络零基础课程
Karpathy神经网络零基础课程
最新评论
开源的AI对话监控面板很实用,正好团队在找这类工具。准备试用一下。
折叠屏市场确实在升温,不过售罄也可能是备货策略。期待看到实际销量数据。
从磁盘I/O角度解释B树的设计动机,这个切入点很好。终于理解为什么数据库不用二叉树了。
IT术语转换确实是个痛点,之前用搜狗总是把技术词汇转成奇怪的词。智谱这个方向值得期待。
这个工具结合LLM和搜索API的思路很有意思,正好解决了我在做知识管理时遇到的问题。请问有没有部署文档?
这个漏洞确实严重,我们团队上周刚遇到类似问题。建议补充一下如何检测现有项目是否受影响的方法。
从简单规则涌现复杂性这个思路很有意思,让我想起元胞自动机。不过数字物理学在学术界争议还挺大的。
我也遇到了指令跟随变差的问题,特别是多轮对话时容易跑偏。不知道是模型退化还是负载优化导致的。