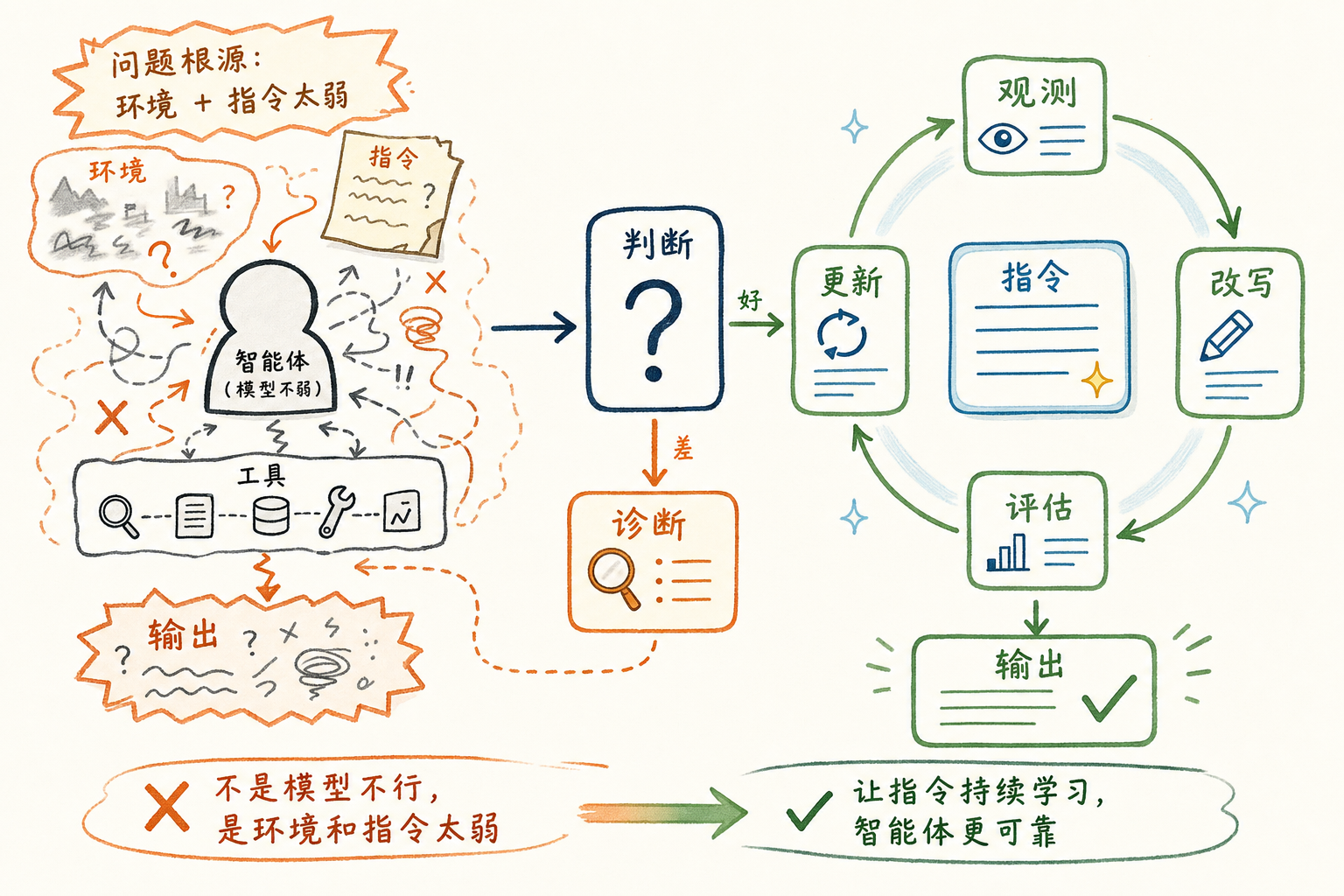
最近半年,业界几乎所有团队都在抱怨 agent 不可靠。模型选了最贵的,工具调用接全了,上下文也尽量塞满,可输出依然时好时坏。换一个模型也救不回来。问题出在哪里?
Arize 的 SallyAnn DeLucia 和 Fuad Ali 在 AI Engineer 大会上做了一个 52 分钟的工作坊,给出的诊断是:绝大多数情况下,模型并不弱,弱的是它身处的环境与被喂的指令。他们把这套方法叫 prompt learning,一个针对 system prompt 的持续学习闭环。

这篇文章不会复述工作坊全程。我想做的是把视频里最值钱的一个判断单独抽出来:prompt learning 真正起作用,不是因为左边那个 agent 优化圈,而是因为很多人没看到的右边那个 eval 优化圈。
失败的起点是 system prompt
工作坊一开始,Sally 问了现场两个问题。第一个:在场有多少人正在搭 agent?几乎所有人都举手。第二个:你们觉得自己搭的 agent 够可靠的,请举手。手齐刷刷放下。
这画面值得记住。它就是行业现状的浓缩。
Arize 团队自己也在搭一个名叫 Alex 的产品内 agent,所以他们对各种失败模式特别敏感。他们把常见的 agent 失败原因拆成三组:
- adaptability / self-learning 缺失:system prompt 写死,agent 不会从历史交互里更新对环境的认知
- determinism 与 non-determinism 失衡:要么完全没 planning,要么 planning 死板到没有任何弹性
- context engineering 不到位:工具缺失、工具选择没指引、关键上下文没传进去
听着像三个独立问题,三组归根结底是同一件事:system prompt 没把规则讲清楚。
他们拿 cline 这个开源 coding agent 做了个对照实验。原始 system prompt 几乎是空的,写的是「You are a cline agent built on this model, you do coding」,完全没有 rules section。改造之后,他们加了一组工程师默认遵守的规则:处理错误时怎么办、修改要对齐系统设计、改动要带测试。仅此而已,没有任何架构调整,没有 fine-tuning,也没有换工具。
结果是在 SWE-bench Lite 上 +15%。
要解释一下 SWE-bench Lite 是什么:它是用真实 GitHub issue 改编的代码修复测试集,把「修一个真实 bug」作为评分任务。业界顶尖模型在上面也就 30%–50% 的水平,每涨 2-3 个点都要被写成新闻。一次性砸进来 15 个点,相当于模型迭代两到三代才能拿到的提升。
更值得留意的是同一批实验里的第二个数据点:原本表现 30% 的 GPT-4.1,在加规则后接近了 GPT-4.5 的水准,而成本只有 4.5 的三分之二。也就是说,你不需要为了让 agent 变好就去抢最新最贵的模型,把规则补齐就能省下一大半推理成本。
这正是这两年 harness 工程领域反复出现的同一个信号,业内有人把它叫 binding-constraint thesis:模型已经不是真实可靠性的瓶颈,harness 才是。LangChain 仅靠改 harness 把 coding agent 在 Terminal Bench 上的排名跳了 20 多位,Vercel 把工具定义从一百多个砍到二十几个,agent 成功率从 80% 拉到 100%,速度还快 3.5 倍。这些都是冻结模型权重、只改外围控制结构的结果。
Sally 总结这一段时说得很朴素:
这是个低投入、高回报的方向。你不用动架构、不用 fine-tune、不用换工具,只动 system prompt,就能拿到大幅提升。
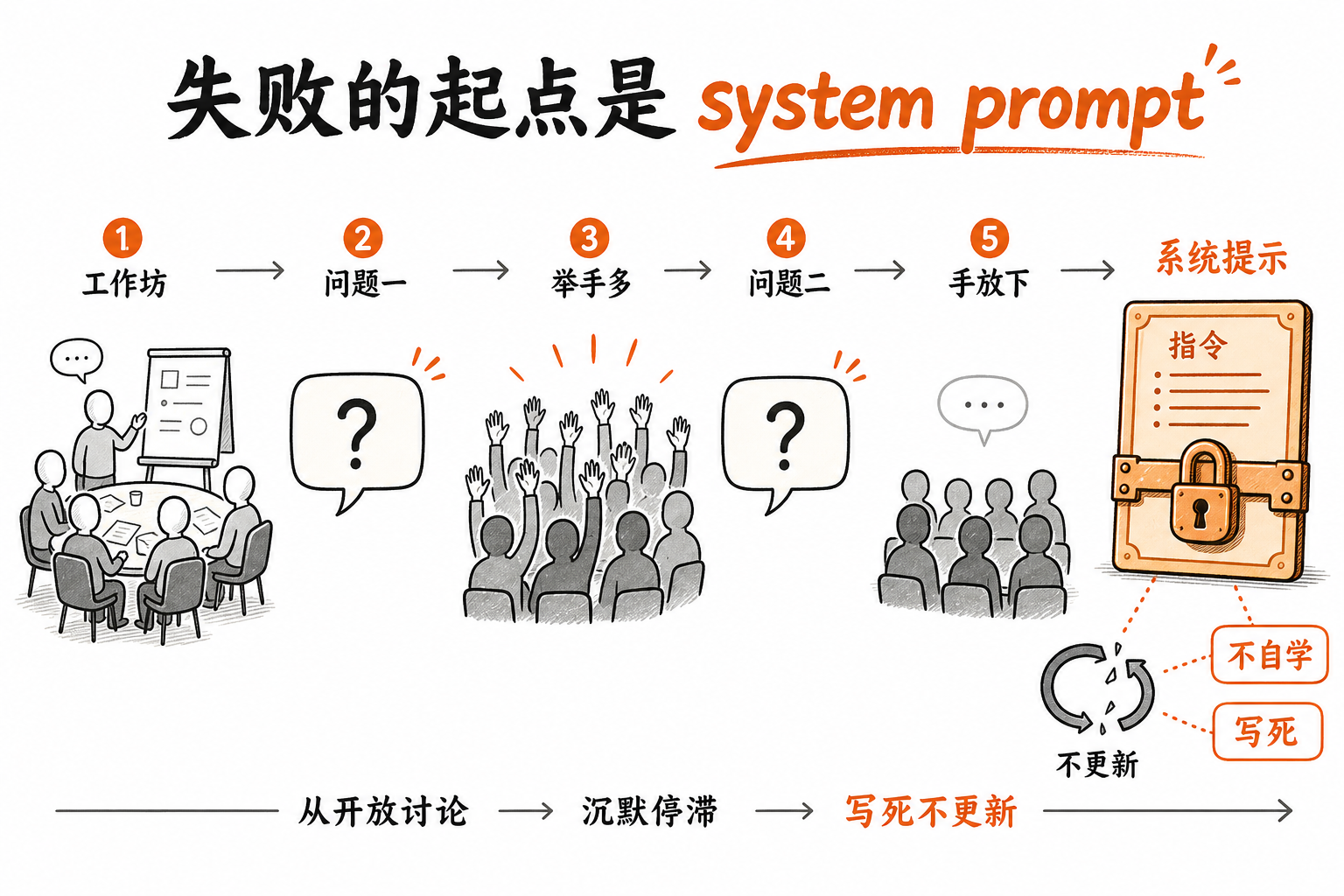
从 RL 到 prompt learning 的三跳
知道 system prompt 这么重要之后,下一个问题就是:怎么让它自己越变越好?
Sally 用一个学生考试的类比把三种方法串了起来。
第一跳是强化学习(RL)。把模型当学生,让它做题,老师改卷给一个分数,学生根据分数更新脑子里的「权重」。这套逻辑在传统 ML 里跑得通,但落到 LLM 上就尴尬了:你没法直接更新 LLM 的权重,更新一次成本极高。
第二跳是 meta-prompting。模型还是那个学生,老师换成了一个「meta-prompt」。学生做题,evaluator 打分,再让 meta-prompt 这个老师根据分数去改写学生用的 prompt。这一跳已经接近 prompt learning 了,但还缺一样东西。
第三跳才是 prompt learning。Sally 在这里强调的差异只有一句话:
The information that we are giving that LLM is quite different.
它和 meta-prompting 的结构几乎一样,agent 做题、evaluator 评分、用另一个 LLM 去改写 system prompt。唯一不同的,是反馈信号从一个 scalar 分数升级成了自然语言解释。不仅告诉你「这题错了」,还告诉你「为什么错」:违反了哪条指令、漏掉了哪个上下文、没遵守哪个边界条件。
这一改看似细微,实际上是把模型的优化材料从一维数轴搬到了文本空间。Sally 的原话是:
这些 LLM 都是在文本空间里工作的。我们有这些丰富的文本可以告诉它具体应该怎么改进,为什么不用它来真正去优化我们的 prompt?
这才是 prompt learning 区别于其它优化方法的核心。最近热度很高的 GEPA,Google 联合 Stanford 提出的进化式 prompt optimizer,也在做类似的事:让一个 reflection LM 去看 evaluator 的反馈、做 prompt mutation。Arize 自己跑了对比:prompt learning 用更少的循环达到了相当甚至略高的精度。差异在哪里?Sally 没有反复强调技术细节,她反复强调的是另一件事。
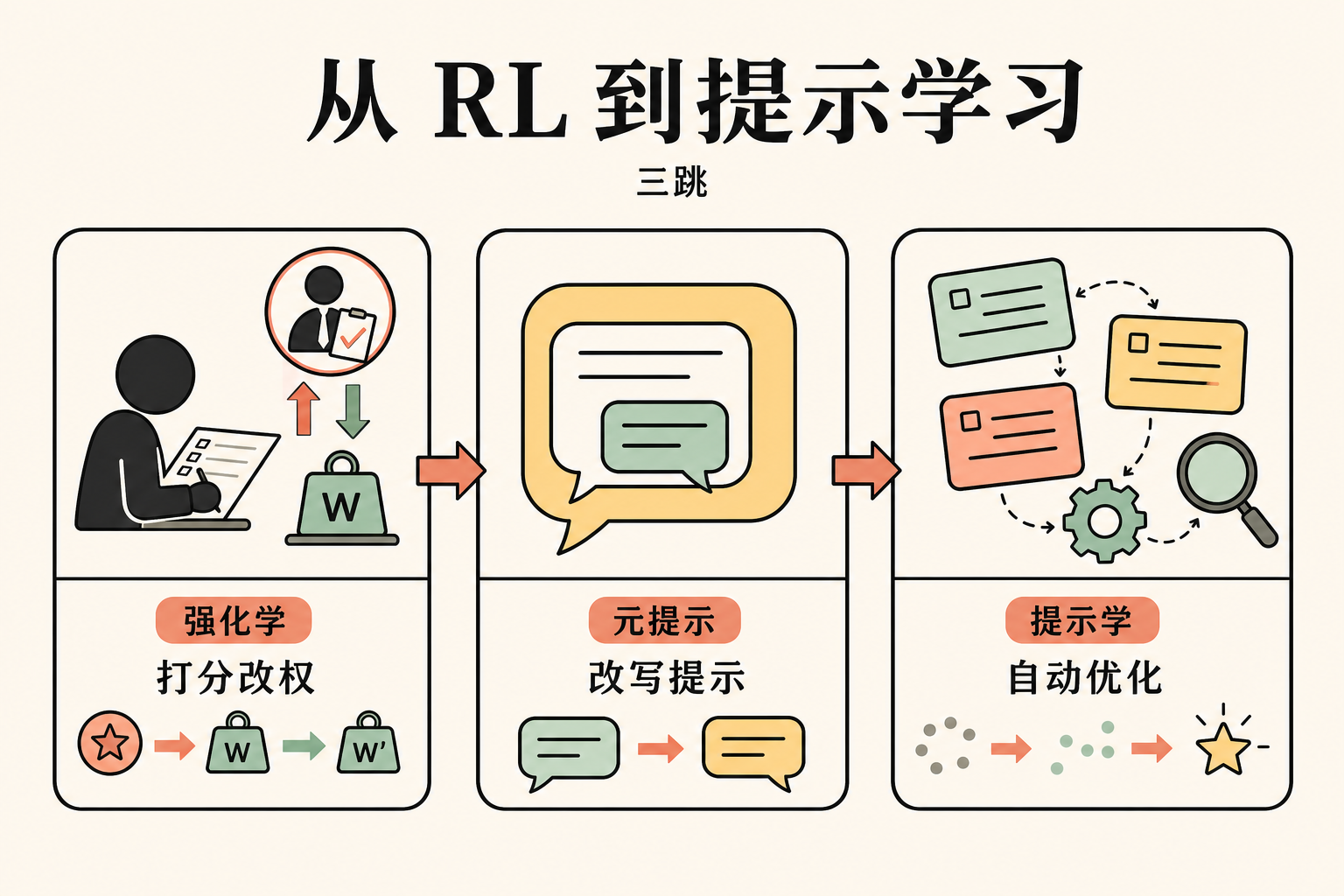
真正的瓶颈:你的 eval 有多准
视频到中段,有人提问:「如果用例不像 coding 那么好量化,prompt learning 怎么用?」
Sally 的回答把问题翻了个面:你最先该问的其实是另一件事,「我的 evaluator 本身可不可靠」。这是工作坊真正的关键点,也是我看完全片之后觉得最值得拎出来单写一段的地方。
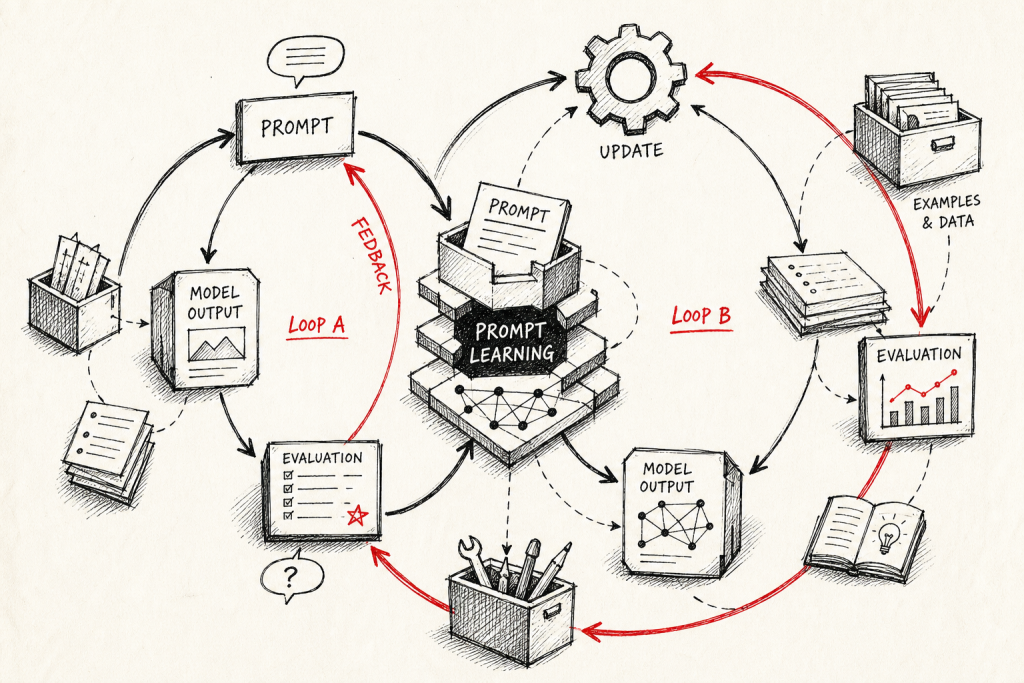
她在白板上画了两个圈。
左边那个圈是大家都在看的:
agent 产出 → evaluator 评分 → 收集失败样本 → 改 prompt → 回到 agent
右边那个圈是大家都忽略的:
evaluator 自己也在评 → 评得准不准? → 收集 eval 出错的样本 → 改 eval prompt → 回到 evaluator
Sally 把它叫做 co-evolving loops,共演化的两个循环。然后她说了一句很重的话:
The left loop only works as well as your eval.
这句话直白翻译就是:右圈不靠谱,左圈做得再漂亮都是假象。
为什么?因为左圈里「失败样本」的认定权完全交给了 evaluator。如果 evaluator 把一个其实正确的回答打成 incorrect,那么「为什么错」的自然语言解释也跟着是错的。拿这种解释去改 system prompt,你优化出来的 agent 只是越来越懂得讨好这个错误的 evaluator。你越跑越偏,还以为指标在涨。
LangChain 2026 年那份产业调查里有一个数据正好能说明这件事:89% 的团队上了可观测平台,能看到 agent 每一步在做什么;但只有 52.4% 的团队真正跑离线评估。剩下那 37% 的差额,就是「看得到、判不准」的灰色地带,trace 数据躺在那里,但没有一套可靠机制把它转化为对错信号。
右圈的搭法跟左圈是完全同构的。Sally 给的方法是这样:
- 不只让人工标对错,要让人工评 evaluator,看 evaluator 给的解释合不合理
- 用 log probability 当置信度,或者用 jury-as-a-judge(多个 LLM 投票)找出 evaluator 自己也犹豫的样本
- 把这些「evaluator 失误」的样本收集起来,标注「为什么错」
- 用同一套 prompt learning 的方法优化 evaluator 自己的 prompt
听上去重,实际上是非做不可。如果你把 evaluator 当成一个「装上就能用」的工具,最后必然栽在第二阶。这就是「把 prompt 当系统」反模式的另一种落地形态:evaluator 也是 prompt,evaluator 不写好同样会失控。
我自己更进一步的理解是:右圈的稀缺度高于左圈,因为它要的是领域专家的二阶判断。左圈里专家只要回答「这个 agent 输出对不对」;右圈里专家要回答「这个 evaluator 的判断对不对,它为什么错」。前者是经验问题,后者是 meta 经验问题。同一批人很少能同时供应这两种判断,组织里需要专门的 review 流程来保证。这也是 Sally 视频里一句反复出现的话的真正含义:eval prompt 值得你像 agent prompt 一样去投入。
overfitting 是 expertise,不是缺陷
这段我觉得可以单独拎出来讲,因为它涉及一个直觉上的反转。
很多人第一次听 prompt learning 都会立刻问:「你拿失败样本去优化 prompt,不就过拟合到这批样本了吗?模型会不会丧失泛化能力?」
Sally 的回答是:
如果你招一个工程师进公司,你恰恰希望他对自己手头这套代码库过拟合。我们换个词叫 expertise,专长。
这个翻转值得停一下。
传统 ML 里 overfitting 之所以坏,是因为模型一旦学死了训练分布就在新分布上失效。prompt learning 优化的对象是 system prompt,是一组工作规则,不是模型权重。工作规则就是该 overfit 的。一个工程师如果非要「通用」到不熟悉自家代码风格、不熟悉历史决策,那叫不专业,不叫泛化。
这一段在工作坊里 Sally 只用了两三分钟带过去,但它把一个长期被误读的概念翻译对了。它呼应了 Karpathy 反复说的那句话:好的 harness 应该让模型的智能变得「对你这件事」更有用,而不是变得「对所有事」更平均。所以 prompt learning 跑的是连续优化,不是一次性优化。随着业务案例不断累积,prompt 也跟着持续吸纳新的规则。Sally 自己把这种持续优化看作一种长程任务,后台一直在跑,不断产出新版本 prompt 推到生产环境。
这套思路对组织的含义比技术细节更值得记住:写 system prompt 不是一次性的开工动作,而是一项持续运营的业务。
把这套 loop 接到我的团队场景里
我们团队做的是机器人云服务,每天有大量 JIRA 工单、巡检报告、错层日志要分诊。最近半年我也在把这些环节往 agent 化推进。看完这个工作坊,我重新审视了自己之前的做法,几件事得改。
第一,evaluator 的优先级要往前提。我之前花在 agent prompt 上的时间远比花在 eval prompt 上多,理由是「eval 嘛,反正人工抽检一下就行」。这其实就是 Sally 警告的反模式。eval 不准,整套 loop 就在自欺欺人地跑。接下来要专门做一遍 eval audit:把每类工单都过一遍 eval 的判断历史,看 eval 自己有多少误判,把误判样本收集起来跑 prompt learning。
第二,反馈不能停在 score。我们之前的 eval 输出基本是 score 加 label,工程师拿到这个分数也分析不出什么。应该把 eval prompt 改成强制输出「为什么对/为什么错」的自然语言解释。这部分文本才是 prompt learning 真正用得上的优化燃料;它会变成下一轮优化的训练信号。
第三,领域专家要被拉进右圈。我们的运维同学才是真正知道哪些工单分诊「看起来对、其实错」的人。这种二阶判断只能他们来做。需要给他们建一个轻量的 evaluator review 界面,让他们标注 evaluator 失误样本,定期反哺到右圈。
第四,rules section 要成为 system prompt 的固定结构。这一条最简单也最容易立刻见效。我们目前的 agent prompt 也是 cline 工作坊前那种状态:身份加任务,没有 rules section。后续会专门给每个 agent 加一个明确的 rules 章节,把团队过去半年积累的「哪里容易翻车」全部写进去。这本来就该是 system prompt 的核心,不是附属。
这四件事里没有一件需要换模型、换框架、换基础设施,全部都是 prompt 这一层能改出来的,跟工作坊的 takeaway 一致:这是个低投入、高回报的方向。
一句话收束
如果只能记住一件事,记这一句:
prompt learning 不是让 LLM 改 prompt,而是把 prompt 改造成一个可验证系统,并且把 eval 也一起拉进这个系统。
左圈大家都看得到。右圈藏在大多数团队的盲区里。哪天你团队的 agent 看上去越优化越糟,先去看右圈。