
本文是《Karpathy神经网络零基础课程》系列文章
← 上一篇:无 | → 下一篇:Karpathy神经网络02:Makemore – 语言模型入门
这不仅是一个视频总结,更是一堂为你量身定制的 AI 原理启蒙课。
视频的作者是大名鼎鼎的 AI 大神 Andrej Karpathy(特斯拉前 AI 总监,OpenAI 创始成员)。他在这堂课里做了一件非常酷的事情:他不只是教你“怎么用”AI,而是带你从零开始,用 Python 代码手写了一个微型的“AI 大脑”——Micrograd。
如果把当今强大的 AI(如 ChatGPT)比作一辆法拉利,那么 Micrograd 就是一个用乐高积木拼出来的迷你电动车。虽然它很小,但它运行的核心原理和法拉利是一模一样的!
以下是为你整理的“初中生也能懂”的 AI 核心原理与造车指南:
🤖 第一部分:核心概念(AI 的“魔法咒语”)
在写代码之前,你需要理解几个让电脑学会思考的关键概念:
1. 导数 (Derivative) = “敏感度”
- 书本定义: 函数在某一点的切线斜率。
- Karpathy 的通俗解释: 想象你在调收音机的音量旋钮。导数就是告诉你:“如果我把这个旋钮(输入)往右稍微拧一点点,音乐声(输出)会变大还是变小?变多少?”
- 在 AI 里,导数告诉我们:如果稍微调整一下神经元的连接强度,最后的预测结果会变好还是变坏。
2. 损失函数 (Loss Function) = “错题本的打分”
- AI 刚开始是“笨蛋”,它猜的答案通常是错的。
- 损失函数用来衡量“它错得有多离谱”。如果在考 100 分的试卷上,AI 预测它是 0 分,那“损失”就很高。我们的目标是把这个“损失”降到最低(接近 0)。
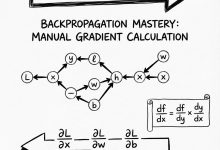
3. 反向传播 (Backpropagation) = “找背锅侠” (全片最核心!)
- 这是 AI 学习的精髓。
- 当 AI 犯错时(损失很高),我们需要知道是谁的错。
- 反向传播就是从最终的错误结果出发,倒着往回推,计算每一个神经元对这个错误负多大责任。如果某个神经元导致错误变大,我们下次就把它调小一点。
4. 链式法则 (Chain Rule) = “传话游戏”
- 如果 A 影响 B,B 影响 C,C 影响最终结果 L。
- 那 A 对 L 的影响是多少呢?就是把每一层的“敏感度”乘起来。这就是反向传播计算错误的数学工具。
🛠️ 第二部分:手把手造“大脑” (详细步骤)
Andrej 在视频中带大家写了一个叫 micrograd 的库,步骤如下:
Step 1: 造砖块 (Value 对象)
我们不能直接用普通的数字。我们需要一种“神奇数字”,它不仅知道自己是多少(比如 3.0),还知道它是怎么来的。
- 比如
c = a + b。在这个神奇数字系统里,c会记得:“我是由a和b通过加法变出来的。” - 目的: 只有记住了来路,我们才能在反向传播时“原路返回”去调整它们。
Step 2: 搭建神经元 (Neuron)
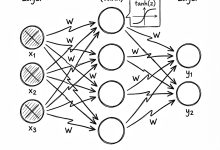
一个神经元就是一个简单的数学公式:
输出 = 激活函数 ( 输入 × 权重 + 偏置 )
- 权重 (Weight): 也就是连接的粗细。这正是 AI 真正“学习”和“记忆”的地方。
- 激活函数 (Activation Function): 视频里用了
tanh。它的作用是把输出限制在 -1 到 1 之间,模拟生物神经元的“激活”状态(要么兴奋,要么抑制)。
Step 3: 组装神经网络 (MLP)
- Layer (层): 把几个神经元排成一排。
- MLP (多层感知机): 把好几层神经元串联起来。
- 这就构成了一个完整的“大脑”网络。
🎓 第三部分:AI 是如何学习的?(训练循环)
这是最精彩的“教学”时刻。Andrej 写了一个循环,让 AI 反复练习。这个过程分为四步,一定要记住:
- Forward Pass (前向传播):
-
把数据丢进网络,让它猜答案。比如给它看图,它猜“这是猫”。
-
Calculate Loss (计算损失):
-
看标准答案。如果其实是“狗”,那就计算它错得有多离谱(Loss)。
-
Backward Pass (反向传播):
- 魔法时刻! 调用
loss.backward()。 -
根据链式法则,计算出网络里成百上千个“权重”旋钮,每一个应该往大调还是往小调,才能让下次猜得更准。
-
Update (更新参数):
- 把所有“权重”旋钮按照刚才算出来的方向,稍微拧动一点点(这叫梯度下降)。
重复这个过程 20 次、100 次……你会发现 Loss 越来越小,AI 从瞎猜变成了神算子!
⚠️ 专家级细节:一个价值百万的 Bug
在视频最后,Andrej 故意(或者不小心)犯了一个经典的错误,这是给初学者的重要一课:
- 错误: 他忘记在每一轮训练前“清零梯度” (
zero_grad)。 - 后果: 就像你做算术题,做完第一题没擦黑板,直接在上面叠着写第二题,结果数字全乱套了。在代码里,这意味着上一轮的“错误指引”累加到了这一轮,导致 AI 学习方向跑偏。
- 教训: 在调用
backward()之前,一定要把之前的梯度清零!这是写 AI 代码最容易犯的错。
📝 总结与思考
看完这个视频,你不再是一个只会调用工具的“调包侠”,你已经理解了 AI 的灵魂:
- 神经网络本质上就是一堆数学表达式。 没有任何黑魔法,只有加减乘除和微积分。
- AI 的学习过程就是“不断试错”。通过微积分(导数)来指引方向,一点点修改自己的参数。
- Micrograd 和 PyTorch (最流行的 AI 框架) 原理一样。 你学会了这个,就等于看懂了现代 AI 的基石。
给初中生的建议: 不要被“微积分”这个词吓跑!Andrej 在视频里证明了,只需要高中甚至初中的代数知识,配合代码,你就能直观地看到数学是如何让机器产生智慧的。
视频链接:https://www.youtube.com/watch?v=VMj-3S1tku0








 程序员数学扫盲课
程序员数学扫盲课 AI周刊:大模型、智能体与产业动态追踪
AI周刊:大模型、智能体与产业动态追踪 Claude Code 全体系指南:AI 编程智能体实战
Claude Code 全体系指南:AI 编程智能体实战 Karpathy神经网络零基础课程
Karpathy神经网络零基础课程
最新评论
开源的AI对话监控面板很实用,正好团队在找这类工具。准备试用一下。
折叠屏市场确实在升温,不过售罄也可能是备货策略。期待看到实际销量数据。
从磁盘I/O角度解释B树的设计动机,这个切入点很好。终于理解为什么数据库不用二叉树了。
IT术语转换确实是个痛点,之前用搜狗总是把技术词汇转成奇怪的词。智谱这个方向值得期待。
这个工具结合LLM和搜索API的思路很有意思,正好解决了我在做知识管理时遇到的问题。请问有没有部署文档?
这个漏洞确实严重,我们团队上周刚遇到类似问题。建议补充一下如何检测现有项目是否受影响的方法。
从简单规则涌现复杂性这个思路很有意思,让我想起元胞自动机。不过数字物理学在学术界争议还挺大的。
我也遇到了指令跟随变差的问题,特别是多轮对话时容易跑偏。不知道是模型退化还是负载优化导致的。