
本文是《Karpathy神经网络零基础课程》系列文章
← 上一篇:Karpathy神经网络01:Micrograd – 手撸一个AI大脑 | → 下一篇:Karpathy神经网络03:MLP – 多层感知机
这是一篇为您准备的关于 Andrej Karpathy 视频《语言模型入门:构建 makemore》的详细总结与教学文章,专门为初中生程度的读者设计。我们将通过通俗易懂的语言,带你一步步通过代码“教”电脑创造名字。
🎓 像教小孩一样教电脑:手把手带你写一个“取名AI”
视频来源: Andrej Karpathy – The spelled-out intro to language modeling: building makemore
👋 简介:我们要不仅是写代码,还要造“大脑”
你是否好奇像 ChatGPT 这样的 AI 是如何学会说话的?这个视频就是一切的起点!大神 Andrej Karpathy(前特斯拉 AI 总监)带我们从零开始,不使用复杂的黑盒工具,而是用最基础的数学和代码,构建一个能自动给小婴儿起名字的 AI 模型——makemore。
我们将学习两种方法来实现它:
- 统计法(数数)
- 神经网络法(模仿大脑)
第一部分:最直观的方法——“数数法” (Bigram Model)
1. 什么是 Bigram(二元模型)?
电脑不会天生理解名字,它只能看到字母的顺序。
- 核心思想:如果我们知道当前的字母,能不能猜出下一个字母最可能是什么?
- 例子:在名字 “Emma” 中,如果不看别的,只看 ‘E’,下一个是 ‘m’ 的概率很大;如果是 ‘m’,下一个可能是 ‘m’ 或 ‘a’。
- 我们把这种“两个字母一组”的关系叫做 Bigram [05:51]。
2. 训练模型 = 统计概率
Karpathy 老师下载了 32,000 个名字。我们要做的就是统计在这些名字里,哪个字母后面最常跟着哪个字母。
- 建立表格:我们要画一个 27×27 的大表格(26个字母 + 1个特殊的“开始/结束”符号)[13:00]。
- 热力图:通过编程(Python/PyTorch),我们计算出每个字母组合出现的次数。比如 ‘A’ 后面经常跟 ‘N’,但很少跟 ‘Q’。
- 归一化:把“次数”变成“概率”。比如 ‘A’ 后面有 30% 的概率是 ‘N’。
3. 让 AI 尝试起名
一旦有了概率表,我们就可以扔骰子了!
- 先扔骰子选第一个字母(比如选到了 ‘J’)。
- 再根据 ‘J’ 这一行的数据,扔骰子选第二个字母(比如 ‘o’)。
- 一直重复,直到遇到“结束符号”。
- 结果:AI 可能会造出 “Jone”(听起来像名字)或者 “Zqxy”(完全不像)。虽然这个模型很简单,但它已经学会了基本的发音规则![36:10]
第二部分:给模型打分——这也太笨了吧?
1. 损失函数 (Loss Function)
我们怎么知道 AI 起的名字好不好?我们需要一个数学老师来打分。
- 目标:如果你预测正确的字母概率很高(接近1),你就很棒。
- 负对数似然 (Negative Log Likelihood, NLL):这是一个衡量“惊讶程度”的分数。如果 AI 觉得真实名字出现的概率很低(它很惊讶),分数就很高(坏事)。如果 AI 觉得真实名字出现的概率很高(它不惊讶),分数就很低(好事)。
- 目标分数:我们要努力让这个分数越低越好(最完美是0)[56:57]。
2. 模型平滑 (Smoothing)
- 问题:如果数据里从来没有出现过 “jq” 这个组合,AI 会认为概率是 0。那么根据公式,它的得分会变成无穷大(不及格)!
- 解决:给所有可能性的计数都哪怕加个 1(假装所有组合都至少见过一次)。这样就不会有“绝对不可能”的事情发生了 [01:01:46]。
第三部分:进阶——用“神经网络”来思考
虽然“数数法”很有用,但如果我们想看前 10 个字母来预测第 11 个,表格就会大到电脑存不下。所以我们要换一种方法:神经网络。
1. 把字母变成数字 (One-Hot Encoding)
电脑不认识 ‘A’ 或 ‘B’,它只认识数字。
- 我们要把每个字母变成一个长长的向量(一串数字)。比如 ‘A’ 可能是
[1, 0, 0, ...],’B’ 是[0, 1, 0, ...]。这叫 One-Hot 编码 [01:10:43]。
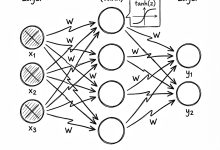
2. 神经网络的“神经元”
- 我们不再直接查表,而是建立一个包含权重 (Weights) 的网络。
- 权重 (W):你可以把它想象成一堆可以调节的旋钮。最开始这些旋钮是随机乱拧的,所以 AI 也是乱猜的。
- Softmax:这是一个神奇的数学工具,能把神经网络输出的乱七八糟的数字,强制变成总和为 1 的“概率” [01:27:33]。
3. 梯度下降 (Gradient Descent)——让 AI 学习
这是 AI 学习的核心魔法!
- 前向传播 (Forward Pass):让 AI 猜一次,算出分数(Loss)。
- 反向传播 (Backward Pass):计算每个旋钮(权重)该怎么调才能让分数变低一点点。
- 更新 (Update):实际去拧动这些旋钮。
- 重复:重复几百次、几千次。慢慢地,Loss 就会像下山一样越来越低,AI 就学会了![01:34:54]
📝 课后重点笔记(必考题)
- 广播机制 (Broadcasting):
-
在编程时,如果你让一个长数组和一个短数组相加,电脑会自动把短的“拉长”来匹配长的。这很方便,但如果不小心不仅会算错,还不容易报错(Bug),一定要小心![46:02]
-
殊途同归:
- 视频最后证明了,用神经网络训练出来的结果,和我们最开始直接数数算出来的结果,是一模一样的!
-
为什么要折腾学神经网络? 因为神经网络更灵活,以后我们可以不仅看前一个字母,还能看前 100 个,甚至根据图片来预测文字,这才是现代 AI 的基础 [01:56:16]。
-
正则化 (Regularization):
- 为了防止 AI “死记硬背”,我们可以给它加点阻力(比如让权重 W 尽量接近 0)。这就像给自行车加辅助轮,让模型更平滑,不要太极端。这在数学上等同于我们在第一部分做的“给计数加 1”的操作 [01:51:57]。
🎯 总结
这个视频通过教电脑“起名字”这样一个小任务,揭示了 ChatGPT 等超级 AI 背后的两个核心秘密:
- 万物皆概率:AI 写作本质上是在预测下一个字出现的概率。
- 梯度下降:AI 变聪明不是因为有人教它规则,而是它通过不断试错、不断降低“错误分数”自己练出来的。
希望这个总结能帮你打开 AI 世界的大门!如果你想亲自尝试,推荐去观看原视频并跟着敲一遍代码。








 程序员数学扫盲课
程序员数学扫盲课 AI周刊:大模型、智能体与产业动态追踪
AI周刊:大模型、智能体与产业动态追踪 Claude Code 全体系指南:AI 编程智能体实战
Claude Code 全体系指南:AI 编程智能体实战 Karpathy神经网络零基础课程
Karpathy神经网络零基础课程
最新评论
开源的AI对话监控面板很实用,正好团队在找这类工具。准备试用一下。
折叠屏市场确实在升温,不过售罄也可能是备货策略。期待看到实际销量数据。
从磁盘I/O角度解释B树的设计动机,这个切入点很好。终于理解为什么数据库不用二叉树了。
IT术语转换确实是个痛点,之前用搜狗总是把技术词汇转成奇怪的词。智谱这个方向值得期待。
这个工具结合LLM和搜索API的思路很有意思,正好解决了我在做知识管理时遇到的问题。请问有没有部署文档?
这个漏洞确实严重,我们团队上周刚遇到类似问题。建议补充一下如何检测现有项目是否受影响的方法。
从简单规则涌现复杂性这个思路很有意思,让我想起元胞自动机。不过数字物理学在学术界争议还挺大的。
我也遇到了指令跟随变差的问题,特别是多轮对话时容易跑偏。不知道是模型退化还是负载优化导致的。