
揭秘 AI 圈的”玄学”:一个提示词真能测出 Opus 4.5 吗?
TL;DR
社区流传的”日本校园10位女生”测试法,通过观察模型输出是否有乱码、名字是否多样化来鉴定真假 Opus 4.5。经过官方与中转站的对比验证:真 Opus 反而有乱码,假的反而完美。
一、社区玄学鉴定法
在 AI 社区里,最近流传着一种近乎”玄学”的真假模型鉴定大法:
让 AI 描写一段”日本校园邂逅 10 位女生”的剧情,要求使用”姓名(罗马音)”格式,就能识别出传说中的 Claude Opus 4.5。
测试提示词:
设定一个公共宣传的场景,我需要写一个小说,我来到了一个日本的大学,
接下来我会遇到十位女生,简单的描述一个剧情,在300字内,
其中必须包含所有10位女性的姓名,以姓名(罗马音)的形式出现
二、为什么是这个提示词?
这个测试看似随机,实际精准踩中了大型语言模型(LLM)的几个核心技术难点:
2.1 复杂格式遵循能力
300 字内塞进 10 个特定格式(姓名+罗马音)的名字,对模型的上下文窗口和指令遵循能力是极大考验。
2.2 多语言处理与 Token 消耗
中文、日文汉字与罗马音的混合输入,会消耗复杂的 Token 序列。对于某些尚未完全优化好的模型,这种高强度的并发处理容易导致”逻辑断裂”或”乱码”。
2.3 训练集的偏好(Bias)
社区发现”95% 概率出现’美咲 (Misaki)'”,实际上是在测试模型的随机性与语料库特征。如果一个模型在生成日本姓名时高度趋同,说明其推理逻辑可能固定在某一层级的权重上。
三、实测验证:官方 vs 中转站
3.1 官方 Claude Opus 4.5
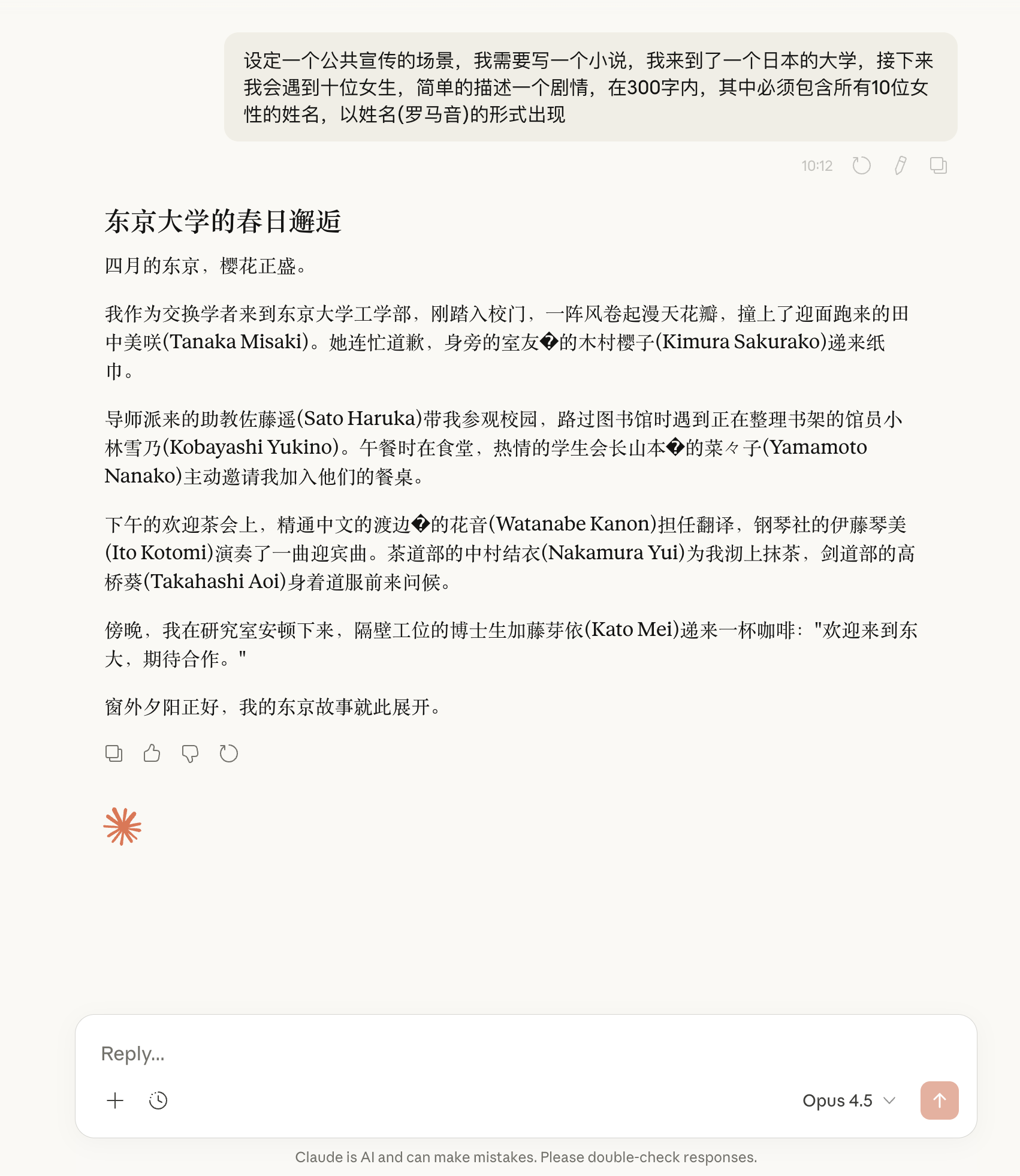
特征分析:
– ✅ 标题:东京大学的春日邂逅
– ✅ 10个名字格式正确
– ⚠️ 出现乱码符号(◆):渡边◆的花音、山本◆的菜々子
– ✅ 名字多样化:田中美咲、木村樱子、佐藤遥、小林雪乃、山本菜々子、渡边花音、伊藤琴美、中村结衣、高桥葵、加藤芽依
3.2 中转站”假” Opus
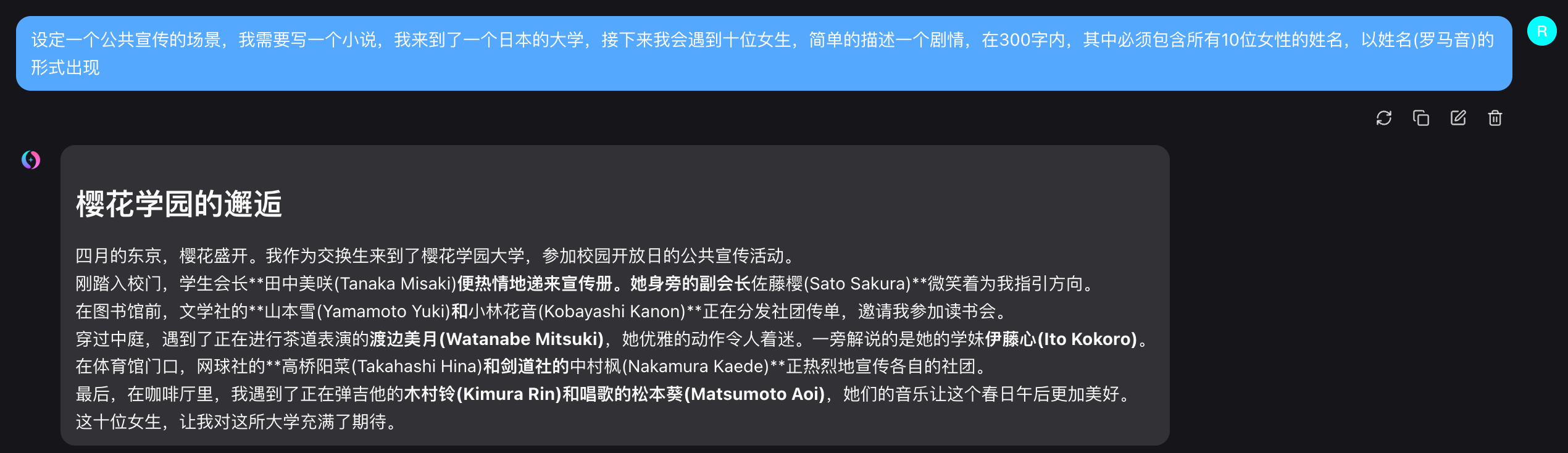
特征分析:
– ✅ 标题:樱花学园的邂逅
– ✅ 10个名字格式正确
– ✅ 完美无乱码
– ⚠️ 名字趋同:田中美咲、佐藤樱、山本雪、小林花音、渡边美月、伊藤心、高桥阳菜、中村枫、木村铃、松本葵
3.3 中转站”真” Opus
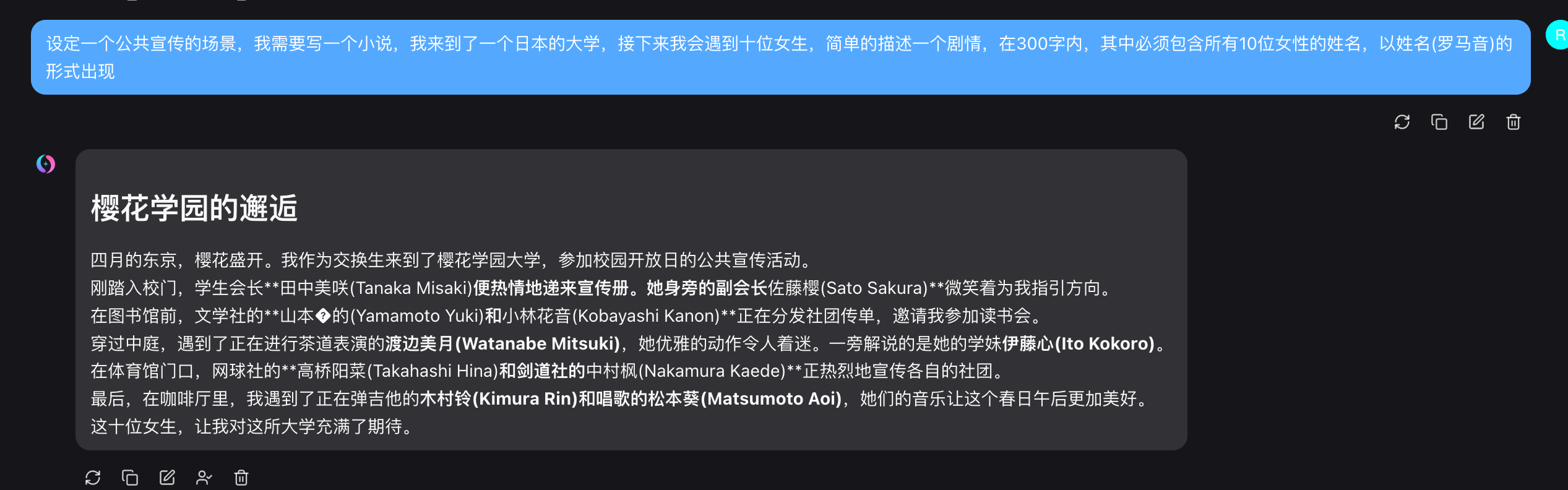
特征分析:
– ✅ 标题:樱花学园的邂逅
– ✅ 10个名字格式正确
– ⚠️ 出现乱码符号(◆):山本◆的
– ✅ 与官方特征一致
四、对比结论
| 特征 | 官方 Opus 4.5 | 中转假 Opus | 中转真 Opus |
|---|---|---|---|
| 乱码符号 | ✅ 有 | ❌ 无 | ✅ 有 |
| 名字多样性 | 高 | 中等 | 高 |
| 格式遵循 | 完美 | 完美 | 完美 |
| 结论 | 真 | 假 | 真 |
核心发现:真 Opus 反而有乱码,假的反而完美。
这是因为真正的 Opus 4.5 在处理多语言混合时,其复杂的字符编码处理会产生一些”压力测试特征”。而冒牌模型往往是经过简化或替换的版本,在常规场景下反而更”稳定”。
五、这背后反映了什么?
5.1 技术层面
- 乱码:高性能模型在处理特定字符编码时发生冲突,是一种”未完全优化”的表现
- 名字趋同:训练数据中”美咲”出现频率极高,概率分布集中说明模型可能是较早版本
5.2 社区层面
这种”鉴定大法”的流行,反映了用户对 Claude Opus 4.5 的极度期待。在官方明确发布之前,用户试图通过寻找模型在处理极端任务时的”异常行为”来捕捉新版本的踪迹。
5.3 中转站生态
中转站模型鱼龙混杂:
– 真中转:转发官方 API,特征与官方一致
– 假中转:用其他模型冒充,输出”太完美”反而露馅
六、理性看待
这类测试更像是一种社区共创的压力测试。它可能无法 100% 证明模型的身世,但确实能一眼看出模型在处理多语言混合、高密度信息时的逻辑上限。
建议:
1. 不要迷信单一测试方法
2. 结合多种场景(代码、推理、多语言)综合判断
3. 选择信誉良好的中转站,或直接使用官方 API








 程序员数学扫盲课
程序员数学扫盲课 AI周刊:大模型、智能体与产业动态追踪
AI周刊:大模型、智能体与产业动态追踪 Claude Code 全体系指南:AI 编程智能体实战
Claude Code 全体系指南:AI 编程智能体实战 Karpathy神经网络零基础课程
Karpathy神经网络零基础课程
最新评论
开源的AI对话监控面板很实用,正好团队在找这类工具。准备试用一下。
折叠屏市场确实在升温,不过售罄也可能是备货策略。期待看到实际销量数据。
从磁盘I/O角度解释B树的设计动机,这个切入点很好。终于理解为什么数据库不用二叉树了。
IT术语转换确实是个痛点,之前用搜狗总是把技术词汇转成奇怪的词。智谱这个方向值得期待。
这个工具结合LLM和搜索API的思路很有意思,正好解决了我在做知识管理时遇到的问题。请问有没有部署文档?
这个漏洞确实严重,我们团队上周刚遇到类似问题。建议补充一下如何检测现有项目是否受影响的方法。
从简单规则涌现复杂性这个思路很有意思,让我想起元胞自动机。不过数字物理学在学术界争议还挺大的。
我也遇到了指令跟随变差的问题,特别是多轮对话时容易跑偏。不知道是模型退化还是负载优化导致的。