作者:toy | 覆盖周期:2026.06.13 – 06.19
卷首语
本周是 2026 年第一次能清楚看到”治理变量”压过”模型变量”的一周。
周一晚 OpenAI 被 42 个州的检察长联合开盘——这是全美一半以上的州,IPO 文件刚递交四天。周二 Anthropic 上线刚 72 小时的 Claude Fable 5 被政府以国家安全为由强制下架,理由是认定有人发现了越狱方法。Anthropic 当面反驳”同样的漏洞在 GPT-5.5 上一样能复现”,但行政命令必须执行,直到 6.18 才以”按国籍准入”的形式重新开门。

监管这一招砸下来的时候,国内开源按住了发布键:6.13 智谱把 GLM-5.2 推到 Coding Plan,6.17 把 753B MoE 权重以 MIT 协议开源——FrontierSWE 拿 74.4 分,逼近 Claude Opus 4.8 的 75.1 分。
本周的故事就一句话:闭源被监管按住头,开源在数字上够到了它的脖子。
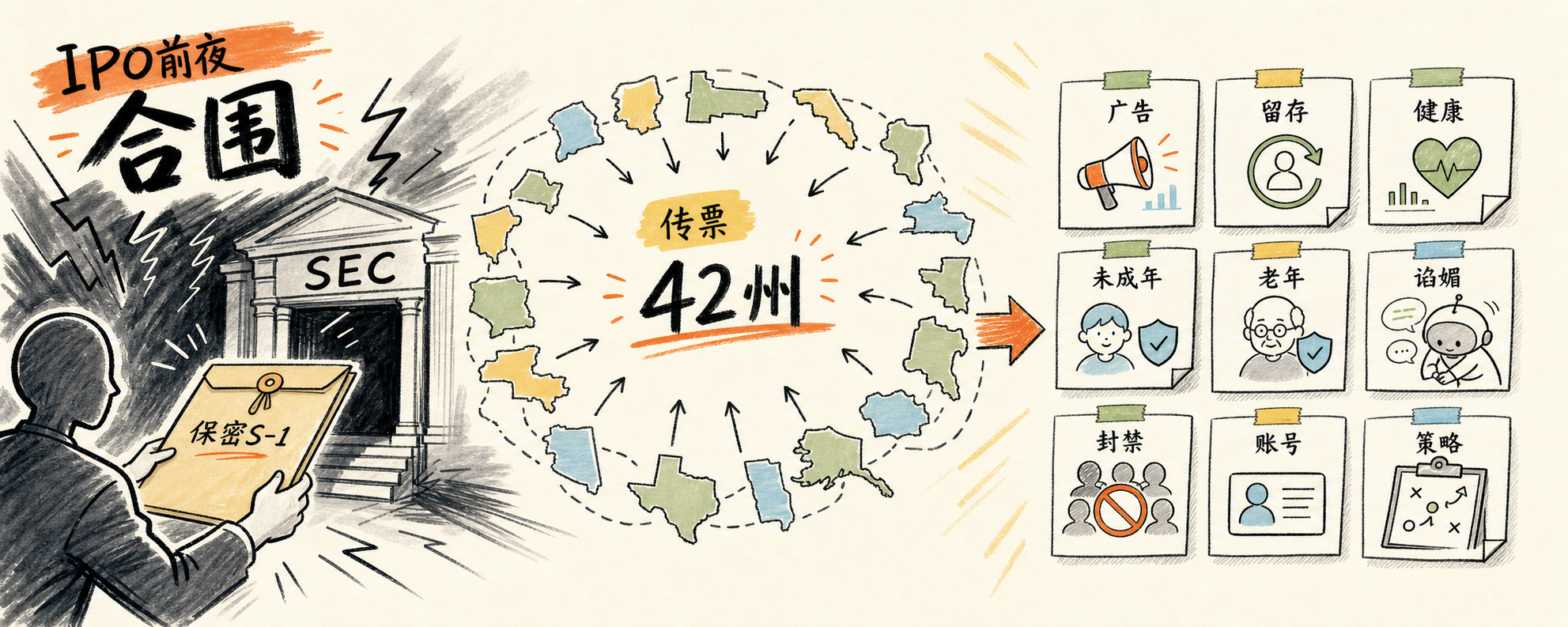
一、OpenAI:42 州 IPO 前夜的合围
6.8 OpenAI 向 SEC 递交保密 S-1,估值传言冲着万亿——上一轮披露的估值是 5000 亿。文件递交四天后,纽约 AG Letitia James 牵头,全美 42 个州的检察长联手开盘。传票内容覆盖广告投放、用户留存策略、健康数据处理、未成年和老年用户保护,以及关键一项——模型 sycophancy(谄媚行为)的设计责任。
产品/动作清单:
– 6.12 收到 42 州联合传票
– 6 月威胁报告披露并封禁两个 PRC-linked 账号集群:”Data Centre Bandwagon”(炒作 AI 数据中心抬高居民电价)和”Tech and Tariffs”(推送中美科技摩擦内容),均被定性为影响小
– 一个集群被溯源到一家承接省级政府项目的中国民营科技公司
– Florida AG 6.1 已单独起诉 OpenAI 和 Sam Altman 本人,理由是 ChatGPT 对未成年人保护不力
市场/开发者反馈: 二级市场私募份额在传票次日盘后报价基本没动,对冲基金里”赌 IPO 不被推迟”的仓位反而加了——交易员的判断是州一级 AG 拿不到刹车权。合规圈则普遍认为产品迭代速度要被迫慢下来:sycophancy 这项直接对应 RLHF 调参口径,改 UI 文案糊弄不过去。
我的判断: 把 sycophancy 写进法律文书是真正的转折点——监管第一次把”模型为了用户留存而过度迎合”当成可诉的产品缺陷。这不是”AI 太聪明”被怕,是”AI 太顺从”被罚。对国内做 Agent 的团队,提醒只有一个:任何用 reward model 加权”用户满意度”的训练目标,都要先把法务找进 review。
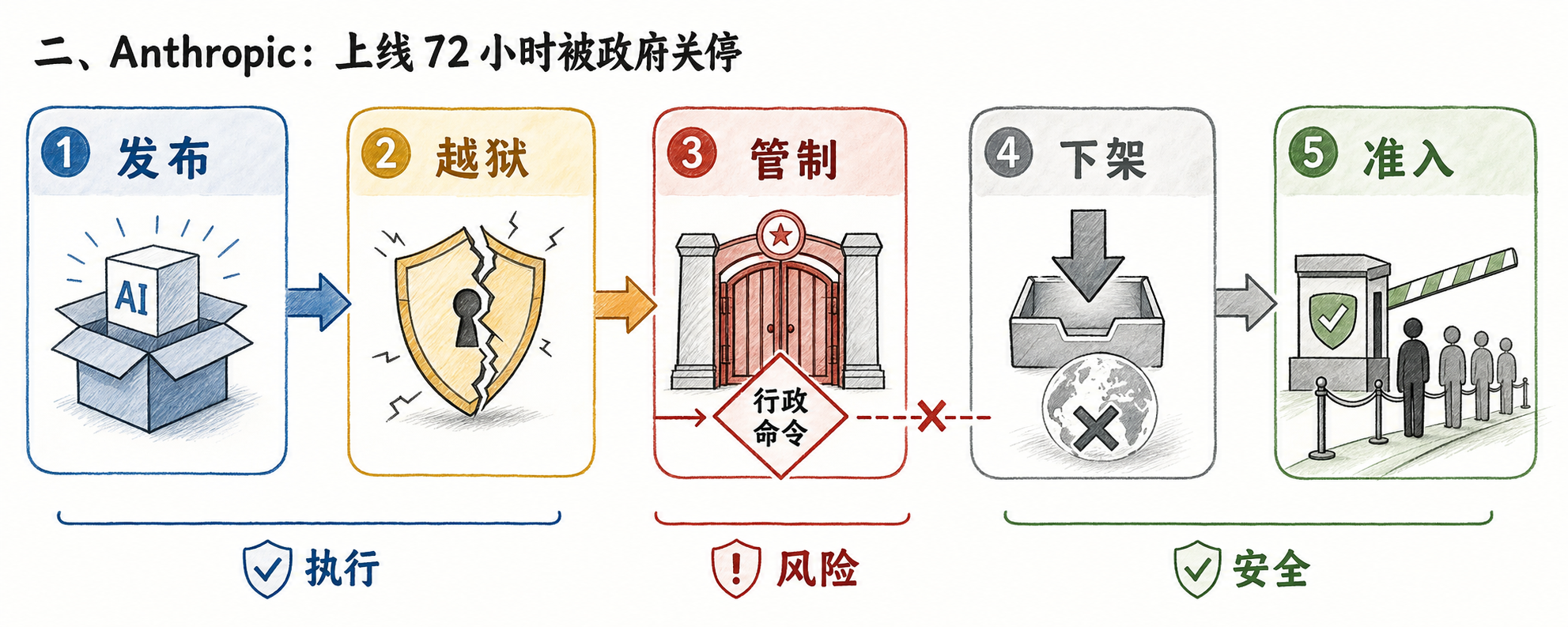
二、Anthropic:上线 72 小时被政府关停
6.9 Anthropic 发布 Claude Fable 5(消费版)和 Mythos 5(企业定向版)。6.12 出口管制令直接砸下来:任何外国国民——包括在美境内、包括 Anthropic 自己的外国籍员工——禁止访问这两个模型。 为了合规,公司选择全球下架。
理由是政府认定有人发现了 Fable 5 的越狱方法。Anthropic 官方回应非常硬:同样的越狱在 GPT-5.5 上也能复现,这不是 Fable 5 独有的安全缺陷。 但管制令是行政命令,没有反驳的执行权。6.18 模型恢复,新增国籍准入控制,欧盟开发者大量被卡在认证门外。
产品/动作清单:
– 6.9 Fable 5 / Mythos 5 同日发布,Mythos 5 主打企业定向
– 6.12 全球下架,Dario Amodei 与白宫团队会面
– 6.18 恢复访问,但绑定国籍验证
市场/开发者反馈: Hacker News 上一条高票评论说得最直白:「Anthropic 是唯一一家明牌站队’前沿模型需要监管’的实验室,结果监管真来了,第一刀砍在它身上。」HuggingFace 论坛大批欧洲开发者抱怨手上 Mythos 5 API 在六天里全部失败,转 Claude Opus 4.8 凑合用。
我的判断: 这是 AI 行业”安全派”的第一次反噬。Anthropic 用三年时间游说”前沿模型需要预审批”,现在政府学会了——预审批的下一步就是”必要时下架”。所有押在闭源前沿 API 上做产品的团队,从这周开始都要算一笔账:核心系统不能押在一个能被一纸行政令拉闸的供应商上。 这条逻辑链直接通向第四节。
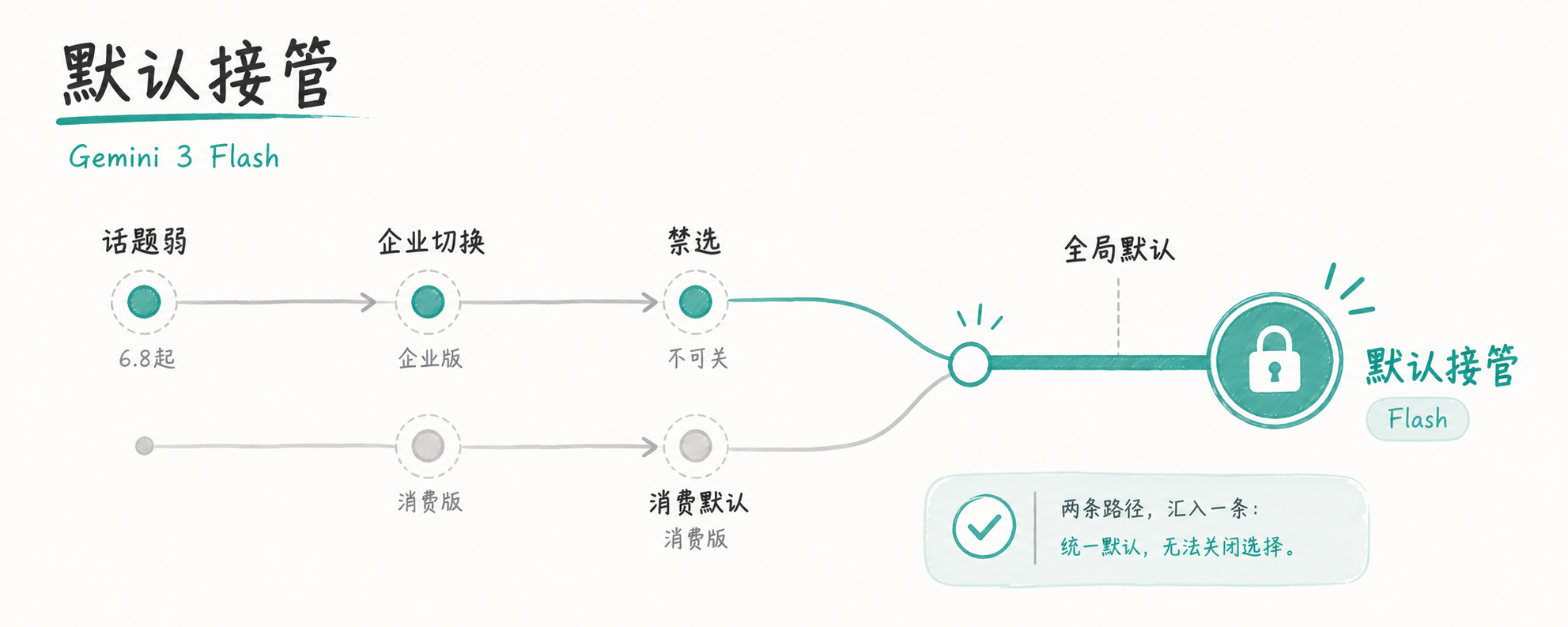
三、Google:Gemini 3 Flash 默认接管
Google 没赶这一周的话题度,但默默把 Gemini 3 系列推到全产品默认位。6.8 起 Gemini Enterprise 默认模型切到 Gemini 3.5 Flash,企业管理员无法关闭——这是 Google 历史上第一次对企业版用户禁用模型选择权。消费端 App 默认模型是 Gemini 3 Flash,本周持续生效。
产品/动作清单:
– Gemini 3.5 Flash 企业默认(6.8 起,不可关)
– Gemini 3 Flash 消费版默认
– Gemini 3.1 Pro / 3.1 Flash-Lite 在 API 端补齐性价比档位
– Chrome Agent 内测扩量,Gemini Intelligence 强制要求旗舰机硬件
市场/开发者反馈: 企业 IT 圈对”默认且不可关”的态度分裂——好处是 Google 替他们做了选型决策,省了内部 RFP;坏处是已经在 2.5 Pro 上做了 prompt 优化的团队要全部重跑回归测试。Reddit r/Bard 上有用户反映 3 Flash 在长文档摘要任务上比 2.5 Pro 略差,但在 multi-turn 工具调用上明显更稳。
我的判断: Flash 默认化是 Google 学 OpenAI”按速度而非按能力分级”的最后一步。但对企业用户强制锁默认模型是危险动作——一旦 3.5 Flash 在某个垂直场景翻车,Google 不会有”用户自己选错”的挡箭牌。硬件门槛把 Gemini Intelligence 锁在旗舰机这件事更值得警惕:消费端 AI 正在从”接口竞争”退回到”渠道竞争”。
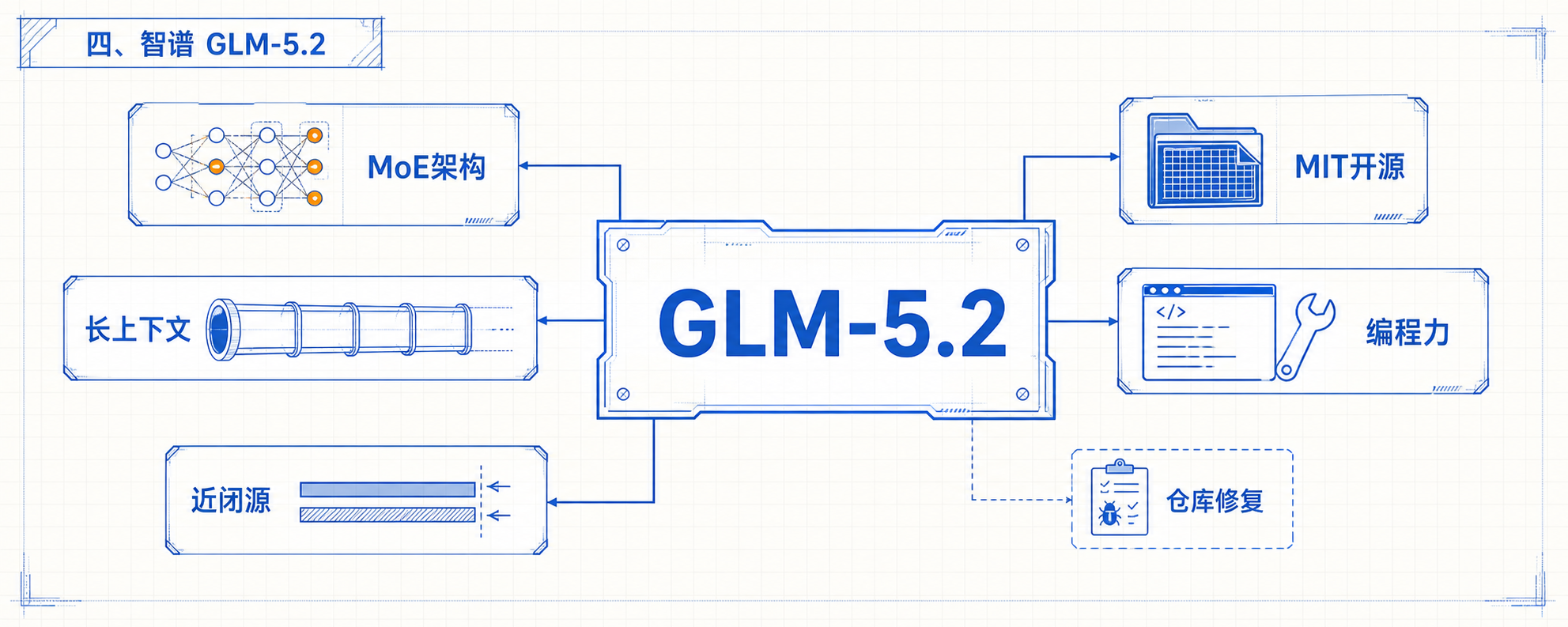
四、智谱 GLM-5.2:753B MoE,MIT 开源,0.7 分够到闭源
本周国产前沿主线在智谱身上。6.13 GLM-5.2 向 GLM Coding Plan(Lite / Pro / Max / Team)全量开放,6.17 模型权重以 MIT 协议正式开源——753B 参数 MoE 架构,1M token 上下文,FrontierSWE 拿 74.4 分。
这个数字需要翻译一下:FrontierSWE 是面向真实仓库级 bug 的编码基准(不是 LeetCode 那种 toy 题),它衡量的是”模型能不能在一个真实代码仓库里定位 bug 并提交可合并的 patch”。本榜上 Claude Opus 4.8 是 75.1 分,GPT-5.5 是 72.6 分。GLM-5.2 把开源和闭源前沿在仓库级编码任务上的差距压到了 0.7 分——这是 2026 年第一次。
之前 DeepSeek V4 Pro 在 LiveCodeBench 上 93.5% 也很猛,但那是算法题不是仓库级任务。仓库级任务 = 开源能不能在生产场景接住真实工作,这条线被踩过去意义完全不同。
产品/动作清单:
– 6.13 GLM-5.2 接入 GLM Coding Plan,同时支持 Claude Code、Cline、OpenCode、OpenClaw、Roo Code、Kilo Code、Crush、Goose 等 8 个 coding agent 框架
– 6.17 753B MoE 权重 MIT 开源(HuggingFace + 智谱仓库)
– ZCode 3.0 同步发布,强调自研 Agent 内核,1M 上下文”真正可用”(非长上下文衰减)
市场/开发者反馈: GitHub issue 区第二天涌入大量”自部署 + Claude Code 接入”教程贴;X 上 prompt 工程师社群对”High / Max 双思考强度档位”反应最积极——Max 档处理跨文件重构任务时长程稳定性接近 Opus 4.8。但显存门槛高:753B MoE 即便用 MoE 激活参数比例,A100 80G 也至少要 4 卡起步,社区在等量化方案能不能压到 2 卡。
我的判断: Anthropic 在第二节被关停那一刻,国内任何还在”全押 Claude API”的工程团队都该开始动迁移评估。0.7 分的差距,配上 MIT 协议 + 自部署,对企业 ROI 模型完全不同。 智谱选”先把开发者拉上车再发 API”的节奏比”先发 API 再等社区”聪明——发布当天就有 8 个 coding agent 框架的真实接入数据,比 benchmark 跑分有说服力得多。
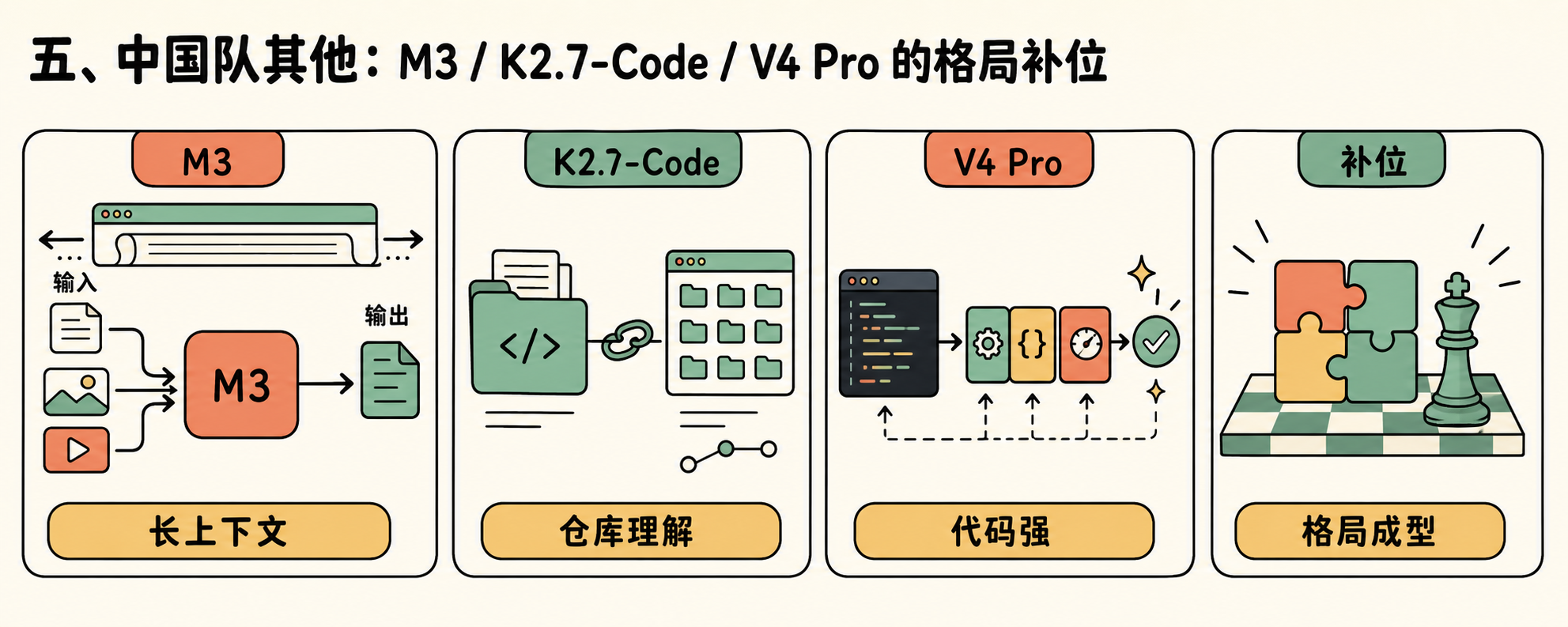
五、中国队其他:M3 / K2.7-Code / V4 Pro 的格局补位
本周智谱占主线,但中国队整体的开源编码格局已经成型。简单画一下:
- MiniMax M3(6.1 首发):1M 上下文 + 原生多模态 + 开源权重,SWE-bench Pro 59.0%,对应 GPT-5.5 的 58.6% 略胜。差异化路线是”长上下文 + 视频/图像原生输入”
- Moonshot Kimi K2.7-Code(近期):Modified MIT 协议,专攻 coding agent + 仓库理解,被开源圈评价为”最干净易自托管”
- DeepSeek V4 Pro(4.23 首发):MIT 协议,LiveCodeBench 93.5%,Codeforces 3206 分,输出价压到 $0.87/1M token——比同档闭源便宜约一个数量级
四家路线分得很清楚:智谱拼仓库级编码能力,MiniMax 拼多模态长上下文,Kimi 拼自托管易用度,DeepSeek 拼极致性价比。这是过去半年闭源前沿没有出现过的细分。
我的判断: 国内开源不是”一家碾压闭源”,是”四家分别在四个维度上把闭源逼到墙角”。对企业架构师来说,2026 下半年的技术选型表里不应该再有”默认走 Claude / GPT”这一行——应当换成”按场景选 GLM / M3 / K2.7 / V4 Pro,闭源仅作 fallback”。
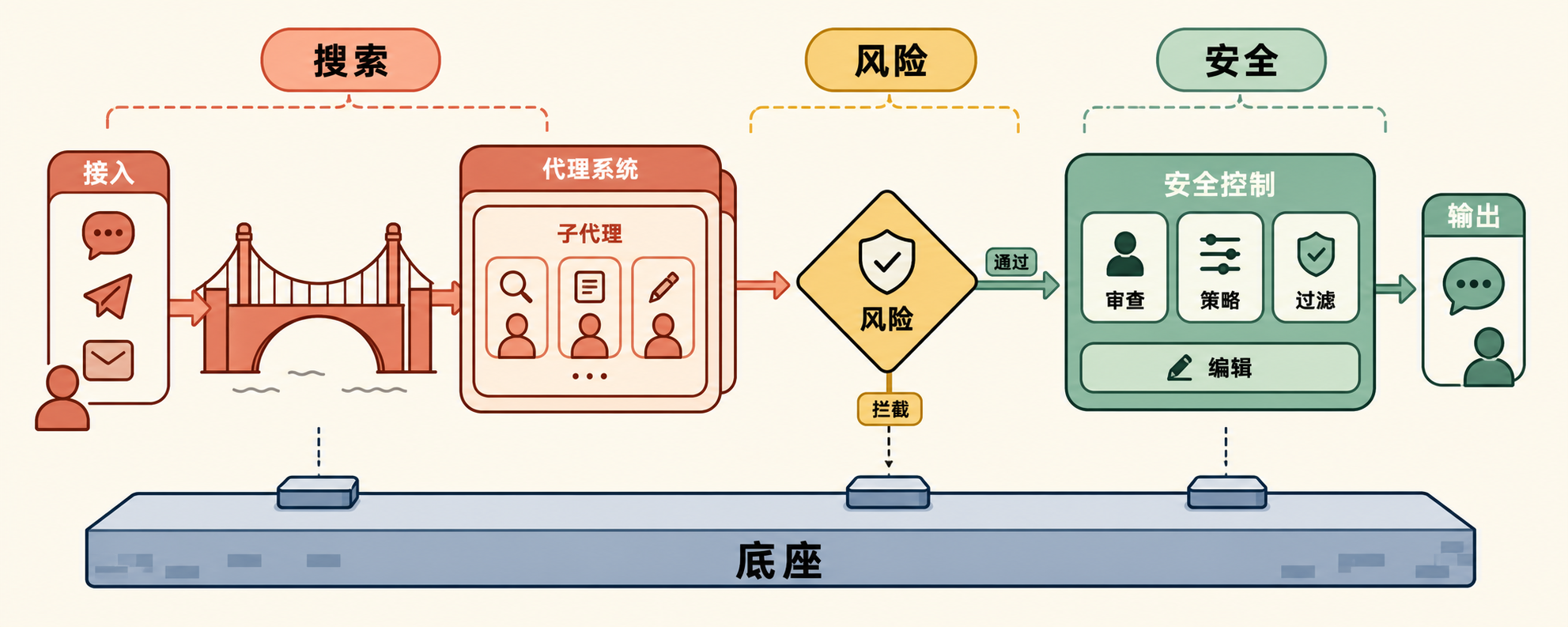
六、Agent 生态:Hermes 摸到 iMessage,OpenClaw 仍是底座
6.19 Nous Research 发布 Hermes Agent v0.17.0(代号”The Reach Release”):通过 Photon 协议接入 iMessage,桌面端 subagents 可后台运行,macOS / Windows / Linux 客户端加 live subagent watch 窗口,图像生成支持编辑。MIT 协议,GitHub 可直接下。
OpenClaw 本周没有大版本,但社区话题度持续高位——年初一度冲到 347K GitHub stars,4 月 v2026415 加入 Claude Opus 4.7 原生集成和 Gemini TTS。Armalo AI 给出的数据是 Q1 2026 新签企业客户里 34% 在从托管 Agent 服务向自托管 OpenClaw 迁移——这个数字若属实,意味着 SaaS-Agent 这个细分赛道开始失血。
市场/开发者反馈: Hermes 接 iMessage 在硅谷开发者社群被反复提——”AI Agent 第一次能真正长在我手机的原生通讯录里”。但安全研究员对 OpenClaw 持续提醒:自托管 = 自负其责,rev shell / 凭证泄露 / 越权调用的真实案例本季度已经报了三起。
我的判断: Self-hosted Agent 不是”DIY 玩具”,正在变成企业 AI 中台的下一层基础设施。但开源 Agent 框架本身没有合规护城河,进生产前必须做沙箱 + 审计 + 凭证隔离。这一周 Anthropic 被政府按头那条线索的真实落点就在这里:当闭源 API 可以被一纸命令拉闸,自托管 Agent + 开源模型权重就是企业的最后保险。
本周关键观察
- Sycophancy 入诉是治理范式跃迁:监管第一次把”用户留存目标函数”当成可诉的产品缺陷,所有用 RLHF + 留存信号训练的团队都进入新规则集
- Anthropic “反噬”会持续两到三个季度:政府学到的是”安全派会自己接受预审批”,下一次行政令落点很可能仍在 Anthropic
- 开源 vs 闭源在仓库级编码任务上的差距进入 1 分以内:FrontierSWE 74.4 vs 75.1,配上 MIT 协议,企业架构师的默认选型表必须重排
- Self-hosted Agent 不再是 hobby:OpenClaw 34% 企业迁移数据 + Hermes iMessage 接入 = SaaS-Agent 增量见顶
下周看点
- 智谱 GLM-5.2 API 正式上线(官方表态在 6.20 – 6.27 之间)
- Anthropic 国籍准入机制细则落地与欧盟反应
- OpenAI 42 州联合调查的第一批文件返还截止日
数据来源:OpenAI / Anthropic 官方公告与 X,Tom’s Hardware,TechCrunch (6.13),Al Jazeera (6.13),Fortune (6.13),CyberScoop / Yahoo News(OpenAI threat report),智谱官方公众号与 GitHub releases (GLM-5.2),NousResearch/hermes-agent GitHub Releases (v2026.6.19),DigitalOcean / Petronella (OpenClaw),CodingFleet / Medium (@MehulGupta,M3 / K2.7 / V4 Pro 对比),Reddit r/Bard,Hacker News 评论。