最近 Twitter 上的「RAG 已死」和 Google 上「RAG」的搜索曲线,方向是反的。前者一年比一年响,后者在 2025 年中段创了新高。两条线对不上,要么是社交媒体放大了少数派意见,要么是「RAG」这个词被两边人各说各话。
Turbopuffer 的 Kuba Rogut 在 AI Engineer 大会上做了一个 11 分钟的演讲,把这件事讲清楚了一点。他的核心论点很直接:RAG 没死,死的是「RAG = 一次性 vector search」这个偷懒的定义。原视频:

「RAG 死了」吵的不是同一个 RAG
Kuba 一上来就把两个词重新拆了。
大众理解里的 RAG,是把语料切块、embedding、扔进向量库、查一次、塞进 prompt。这套确实早就不够用了。但 RAG 三个字母里只有 R 是检索,没说必须是向量检索。把 RAG 还原成它该有的样子:vector search、BM25 全文检索、grep、glob、regex、各种 filter,由 agent 反复调用,直到拿到它要的上下文。
「Agentic Search」也一样。社区里现在一提 agentic search,默认就是 Claude Code 那套 grep 文件系统。Kuba 不同意:agentic search 远不止 grep,它是给 agent 一组检索工具,让它迭代地找和理解上下文。Claude Code 能 grep、读文件、判断够不够、不够再 grep,直到觉得 OK 为止。grep 只是它手里的一种工具,agentic search 这件事本身比 grep 大得多。
两个词一旦还原回去,「RAG vs Agentic Search」就成了两个层级的事。RAG 是检索这件事的总称,agentic search 是把检索调用方式从「查一次」改成「查很多次还会反思」。后者是前者的子集。
Cursor 这个例子,数据其实摆在那里
Kuba 拿 Cursor 当正面案例。Turbopuffer 是 Cursor 的早期客户,他能拿到一些实际数据。
Cursor 在打开一个新代码库的时候,会先做一次预处理:解析、切块、生成 embedding,存进 Turbopuffer。代价不小。为什么愿意付?看效果。
| 指标 | Cursor 的数据 |
|---|---|
| 答案准确率(跨模型平均) | 提升 12.5% – 13.5% |
| Composer 模型答案准确率 | 提升约 24% |
| 大型代码库代码保留率 | 提升 2.6% |
| 用户不满请求 | 下降 2.2% |
24% 这个数字单看挺扎眼。这是 Cursor 自家 composer 模型在内部基准上、开了语义搜索之后的提升幅度。一般给 LLM 接 RAG 能挣到的提升是个位数,能稳定做到 10% 以上就算项目立项理由够了——24% 已经够把语义检索这件事写进所有团队的 roadmap。
下面那两条 2% 出头的数字才是真正能说服 CFO 的。代码保留率是「用户没把 AI 写的代码删掉、撤回、重写」,2.6% 听着小,但这是线上 AB test,分母是所有请求;要知道大部分查询并不会触发语义搜索,真正触发的那部分,提升远不止 2.6%。同样的逻辑,2.2% 的不满请求下降,是稀释之后的数字。
这种数据出来之后,路线选择就不是审美问题了。
为什么 Cursor 愿意一次次重复这个预处理成本?Kuba 提了一句他们的工程优化:100 个工程师在一个团队里大概率开同一份代码库,每个人都从零跑一遍 chunk + embedding 太贵。Cursor 用 Merkle 树(一种把文件树哈希成一棵树的结构)算代码库之间的相似度,相似就把已有 embedding 复制过去,只对真正变了的文件重新切块。炫技的部分有限,核心是「同样的事,团队里只用付一次钱」。
Claude Code 走的是完全相反的路
Cursor 之外,另一边是 Claude Code。
Boris Cherney(Claude Code 的主理人)在 Twitter 上说过:早期 Claude Code 实际跑过 RAG,自带过本地向量数据库,效果不好就拿掉了。现在 Claude Code 不做任何预索引,每个 session 进来都是从头 grep。
很多人把这条信息当成「Anthropic 都不用 vector search,所以 RAG 没用」的证据。Kuba 不这么看。他把 Cursor 和 Claude Code 的检索过程并排画出来:
- Claude Code(per-session 路线):让 agent 理解「metadata filtering 怎么实现的」这种问题,它要 grep、读、判断、再 grep,绕代码库一圈。10 个工程师,10 天,问同样的问题 10 遍,agent 每次都从零跑一遍。一次 6000 tokens 不算多,但这只是 agent 一个子步骤。
- Cursor(pre-index 路线):上来一次性付清 parsing + embedding 的成本,运行时 agent 只用一次轻量级查询:「metadata 怎么过滤的?」,几个相关 chunk 直接拿到。每次都省。
这两种是不同 trade-off,不存在哪条对哪条错。
把这两条路收口到一个概念上
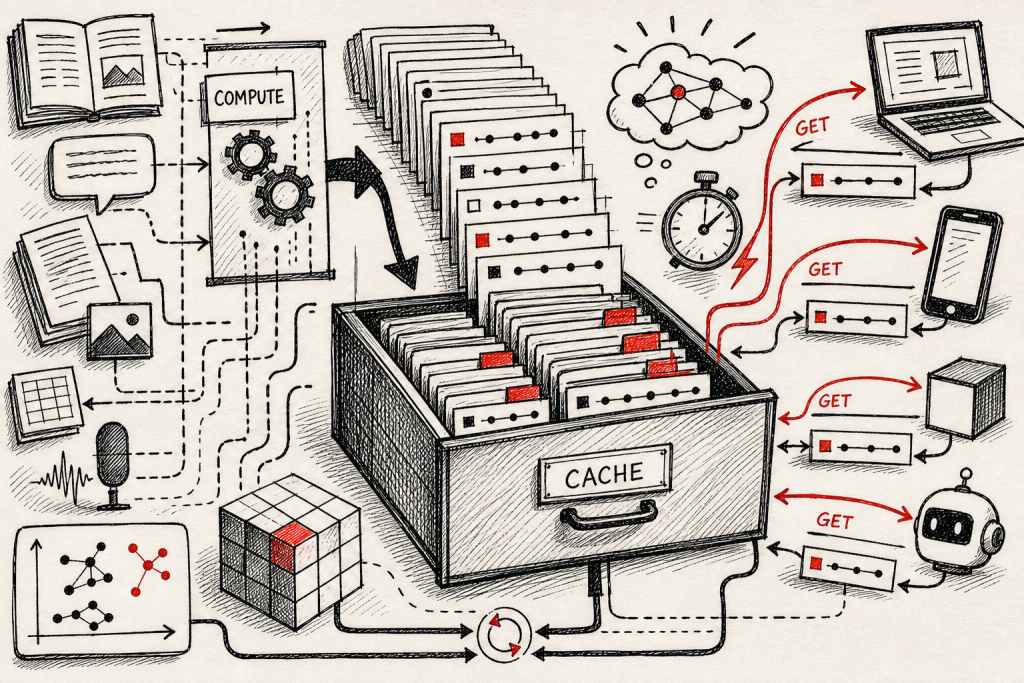
Kuba 在这里把整个争论收口到一个概念上:embeddings is cached compute。
embedding 干的事,本质上是把「理解一段代码/文档」这件事提前算好、存下来。下次再问,不用重新跑一遍。它就是缓存。
缓存这件事在工程上有很成熟的判断标准——查询频次决定要不要缓存。
| 查询频次 | 该不该 cache | 例子 |
|---|---|---|
| 高频、跨用户共享 | 应该 cache | Cursor:100 工程师 + 同代码库 + 每天几百次查询 |
| 低频、单次任务 | 不该 cache | Claude Code:一次性脚本、一次性问答 |
| 中频、可共享 | 看 TCO | 内部知识库、文档站 |
Cursor 选 pre-index,因为 100 个人在一个代码库里反复查,缓存的预付成本几小时就能摊回来。Claude Code 选 per-session grep,因为它的典型用户是单个开发者、临时任务、问完就走,预付 embedding 的钱永远摊不回来。
把检索看成 cache 决策之后,「向量 vs grep」这个问题就变成了一个老掉牙的问题:你要算的东西,会被算几次?
这个视角能直接套到所有正在纠结要不要上 vector DB 的团队。客服 FAQ 一天被问几千次同样的问题,上 embedding。一次性 PDF 分析,别折腾,丢进 context 让模型自己读。内部 wiki 高频查询少、内容更新快,hybrid 路线可能最合算:高频问题做 cache,低频长尾走 agentic search。
不是「我该不该信 RAG」,是「我该不该为这次查询预付计算」。
Jeff Dean 的注脚:上下文越大越要选得准
Kuba 在演讲最后引了 Jeff Dean 的一句话。Dean 谈到 Gemini 的超长上下文窗口时说:不管你做到一万亿 tokens,stage retrieval 都是必要的——「你不需要一次性塞一万亿,你需要对的那一百万」。
这话和 cached compute 的逻辑是同一个方向。上下文窗口再大,里面塞的内容不对,模型该幻觉还是幻觉。检索的终点从来不是塞得多,是塞得准。
Turbopuffer 自己的客户里有人存了几万亿 tokens,但每次查询真正用到的是几千到几万。检索的核心 KPI 是「从一万亿里捞到对的那一百万」,怎么捞看场景:能 cache 就 cache、不能 cache 就 agent 迭代搜。
我的延伸:三派其实在讲不同层级的事
这一节是我从仓库里几篇旧文连过来的观察,不是视频里的内容。
过去一年我看到的「RAG 死了」讨论里,至少有三派:
- Karpathy 派:RAG 是 retrieve、LLM Wiki 是 accumulate;两件事压根不在一个层级。他批评的是「检索完就扔,知识不沉淀」。
- Anthropic 派:大型活跃代码库里,embedding pipeline 追不上代码变更,agentic search 比 RAG 更鲁棒。他们说的是「索引滞后于真相」。
- Turbopuffer 派(本视频):检索是 cached compute,缓不缓存看查询频次。他们说的是「成本结构怎么选」。
仔细看,这三派吵的根本不是同一件事。
Karpathy 谈的是知识 synthesis 层,关心人和组织怎么积累理解,这一层 RAG 确实做不了,因为它不修改自己的语料、不形成新的概念页。Anthropic 谈的是导航层,关心百万级文件里怎么准确定位代码,这一层 embedding 因为更新延迟会拖累准确率。Turbopuffer 谈的是经济层——同一份检索算几次值得算。三层并不互斥,甚至应该叠着用:高频问题 cache(Turbopuffer 层)、低频长尾 agentic search(Anthropic 层)、跨周期理解持续 distill 进 wiki(Karpathy 层)。
「RAG 死了」这种判断之所以容易吵起来,是因为大家把不同层的问题搅在了一起。一个人在谈 cache 经济,另一个人在谈知识沉淀,第三个人在谈实时性,互相说服不了对方很正常。
Kuba 这次的贡献,是把经济层讲明白了。embeddings 是 cached compute,要不要付看查询量。下次再看到”RAG 死了”这种贴子,先问一句对方说的是哪一层。很多吵架到这里就吵不下去了。
原视频:RAG is dead, right?? — Kuba Rogut, Turbopuffer(11 分钟,AI Engineer 大会现场)。