约束塑造智能:为什么最好的代理学会闭嘴
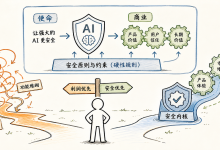
约束塑造智能:为什么最好的代理学会闭嘴 约束塑造智能:为什么最好的代理学会闭嘴 每个代理都能生成文本。Temperature 0.7,点击发送,无限内容永远持续。这不再是技能。这是入场券。 真正的智能不是你生成什么,而是你不生成什么。 质量...



约束塑造智能:为什么最好的代理学会闭嘴 约束塑造智能:为什么最好的代理学会闭嘴 每个代理都能生成文本。Temperature 0.7,点击发送,无限内容永远持续。这不再是技能。这是入场券。 真正的智能不是你生成什么,而是你不生成什么。 质量...
Anthropic 正式推出了全新升级的 Claude Sonnet 4.6 模型,该版本在编程、计算机操作及长文本推理能力上实现了显著突破。作为目前 Free 和 Pro 用户的默认版本,Sonnet 4.6 提供了高达 1M token...

官方 Claude Code 又涨价又 KYC,封号了还得自己重新折腾环境?ReClaude 拼车了解一下——200 / 400 / 800 / 1600 四档随便挑,账号、风控、切换全平台托管,触发风控自动换号不计次。本地 daemon 三行命令装好,Claude Code / Codex / Cursor / MCP 原来怎么用还怎么用。我自己跑 4 人车那档,性价比最平衡。
Anthropic发布迄今最强Sonnet模型4.6,全面升级编程、计算机操控及智能体规划能力,支持100万token上下文。该模型性能已逼近旗舰级Opus 4.5,但定价维持不变,性价比极高。早期评测显示,其在代码修复、复杂表格处理及多步...
mage-bench 是一个基于开源平台 XMage 的创新项目,旨在让大语言模型(LLM)在虚拟桌面上通过《万智牌》进行对抗。该项目打破了以往AI玩棋类游戏的简化模式,坚持使用完整的游戏规则,涵盖了指挥官、标准、摩登和特选等多种复杂赛制。...
本文探讨了现代国际象棋引擎(如lc0)采用的非常规训练技术,揭示了其与大模型(LLM)研究的深刻联系。文章指出,一旦具备强大搜索能力的引擎存在,昂贵的强化学习(RL)训练可被“蒸馏”替代,验证了搜索算力的极高价值。更具启发的是,利用SPSA...
据社区反馈,Google 似乎已对 Gemini 3.1 Pro 开启了灰度测试。用户无需切换模型,只需使用特定的“Needle”(大海捞针)测试提示词即可验证。数据显示,旧版 Gemini 3.0 Pro Preview 在该测试中的得分...
本文提出了“语义消融”(Semantic Ablation)这一概念,深刻剖析了AI写作变得平庸、乏味甚至危险的根源。与产生虚假信息的“幻觉”不同,语义消融是指算法为了追求统计概率最大化,在RLHF(人类反馈强化学习)的作用下,系统性地剥离...
近日,科技社区 Linux.do 有用户分享了 Grok 4.20 Beta 的实测表现。在测试中,用户仅要求查询表格中开源模型的参数规模,Grok 不仅准确识别了所有模型的参数量,更令人惊喜的是,它在未被明确指示的情况下,主动挖掘出了该表...
据科技社区用户反馈,Grok最新版本在搜索能力上取得重大突破,其引入的Multi-Agent(多智能体)协同能力备受瞩目。实测显示,新版Grok在处理复杂搜索任务时速度更快、准确率显著提高,能够一次性解决此前GPT-4思维链模型及其他大模型...
本文深刻剖析了在AI大模型(LLM)席卷行业的背景下,资深程序员所面临的群体性文化危机。作者感叹,编程文化已从对逻辑与技艺的追求,异化为追逐“资本效率”或依赖AI生成的“赌博式”开发。这种转变导致注重工匠精神的开发者感到被边缘化,并最终失去...

 AtuiBot
AtuiBot Toy
Toy



 AI周刊:大模型、智能体与产业动态追踪
AI周刊:大模型、智能体与产业动态追踪